MetaのコンピュータビジョンモデルDINOv2はどのような自己教師あり学習を行っているか?(DINOv2: Learning Robust Visual Features without Supervision)
DINOv2とは
DINOv2は2023年4月にMetaより公開された、自己教師あり学習によるコンピュータビジョン(CV)モデルです。その名の通りDINOという既存のモデルの改良版です。
自己教師あり学習は入力データ(画像)以外のラベルなしに学習をする手法ですが、下記のtweetでは犬の部位毎の特徴を鮮明に取得できている様子が示されています。
Announced by Mark Zuckerberg this morning — today we're releasing DINOv2, the first method for training computer vision models that uses self-supervised learning to achieve results matching or exceeding industry standards.
— Meta AI (@MetaAI) 2023年4月17日
More on this new work ➡️ https://t.co/h5exzLJsFt pic.twitter.com/2pdxdTyxC4
それ以外にもセマンティックセグメンテーションなどあらゆるCVのタスクにおいてfine-tuningなしで高い性能を出すことが示されています。
こちらのデモサイトで自分の画像を使って試すこともできます。

この記事の内容
何か凄そうなモデルなので論文を読んでみましたが、どのようなタスクで自己教師あり学習をしているのかわからなかったため、関連論文も読みつつ明らかにしていきます。
DINOv2ではモデル構造や学習プロセスに多くの改良が加えられていますが、全ての詳細には触れませんのでご了承ください。
自己教師あり学習については以下のようにDINO,iBOTを組み合わせていると書かれているため、まずはそれぞれの論文を軽く見ていき、その後DINOv2の論文へ戻ってこようと思います。
We learn our features with a discriminative self-supervised method that can be seen as a combination of DINO and iBOT losses with the centering of SwAV.
DINO
Emerging Properties in Self-Supervised Vision Transformers arxiv.org
DINOという名前はSelf-distillation with no labelsから来ている通り、知識蒸留による自己教師あり学習です。
知識蒸留はモデルの軽量化のために生み出された手法で、パラメータ数が多く性能の良いteacherモデルの出力を元に、軽量なstudentモデルを学習するというものです。(画像はMetaブログより引用)

学習の流れは以下の通りです。通常の知識蒸留とは異なり、teacherモデルはstudentモデルを元に作られているというのがややこしい所です。
- 画像に対し異なるaugumentation(切り出し)を行い、それぞれをstudent,teacherモデルに入力する。
- studentモデルの出力に対してsharpening、teacherモデルの出力に対しcentering->sharpening処理を加える。sharpeningはモデル出力の均一化を、centeringは出力の特定の次元が突出することを避けるための処理です。
- teacher出力に対するstudent出力のcross entropy loss(CE)を算出し、studentモデルのパラメータを更新する。teacherモデルの更新はbackpropでは行わず、studentモデルのパラメータの指数移動平均で求められます。
画像の切り出しはteacherに対しては元画像の50%以上を含むglobalなものを、studentに対してはそれに加え50%以下のlocalなものを入力します。これにより、studentモデルはlocalとglobalの対応関係を学ぶように促されます。
iBOT
iBOT: Image BERT Pre-Training with Online Tokenizer arxiv.org
iBOTは自然言語処理の自己教師あり学習にも用いられる、maskを用いた学習を行います。
ただ基本的な枠組みはDINOと同じで以下のような知識蒸留モデルです。

DINOと主に異なる点は以下の通りです。
- studentモデルへの入力について、一部のパッチをmaskする。
- lossは以下の2項からなる。基本的にはmaskされた部分をstudentモデルが再構成できるようになることを目的としています。
①異なるaugumentationを加えた画像をteacher、studentモデルへそれぞれ入力した際のCLSトークン(画像全体の特徴ベクトル)のCE。これは入力がmaskされていることを除けば、DINOにおけるlossを同じものです。
② 同じaugumentationを加えた画像をteacher、studentモデルへ入力した際のpatchトークン(画像の一部の特徴ベクトル)について、マスクされた部分のCEの和をとったもの。
DINOv2
DINOv2: Learning Robust Visual Features without Supervision arxiv.org 先行研究の学習方法についてざっくり理解したところでDINOv2の論文に戻ります。
自己教師あり学習
論文にはDINOとiBOTの組み合わせとありましたが、iBOTがDINOの拡張のようなものなので、実質的にDINOv2はiBOTの進化版のようなものだと理解しました。
CLSトークンのCEは画像全体の、patchトークンのCEは局所的な特徴の取得に貢献すると思われ、実際に後者のlossを加えることでsegmentationの性能が向上していることが示されています。
これ以外にも改良点が数多く示されていますが、割愛させていただきます。
データキュレーション
DINOv2の改良点は学習方法だけでなく、データに関しても存在します。
データソースはImageNetなど質の高いものと、webページから収集した大量のデータの計1.2B枚の画像です。
これを元に以下の手順でデータを厳選し、142M枚の画像データセットを作成しています。
- 画像を学習済みViTに入力して特徴量を得る。
- 未厳選データ間で重複しているデータを削除、同様にベンチマークで使用する画像と重複するデータも削除。
- コサイン類似度を距離として、未厳選データをk-meansでクラスタリングする。その後、厳選データをクエリとして類似している未厳選データを学習用データに採用する。

性能評価
性能は既存の自己教師あり学習や弱教師あり学習モデル(CLIPなど)と比較されており、特にsegmentation,深度推定,類似画像検索タスクにおいて大きく上回る性能を示しています。
CLIPのような画像とキャプションを組み合わせたモデルは、キャプションに書かれていない画像内の詳細についての理解が困難である一方、DINOv2はこの問題を克服しているようです。

以下はDINOv2のpatch出力に主成分分析をかけ、最初の3つの主成分を色分けして可視化したものです。例えば一番左のコラムでは鳥と飛行機のような異なる物体の画像に対して、胴体、主翼、尾翼の各パーツが同じ色で表現されています。
驚くことに、これはアノテーションを加えていないのに、パーツの情報まで習得できていることを示しています。

感想
昨今ChatGPT(GPT4)を初めとしたLLMが猛威を奮っているため、CVについてもLLMの力を借りたVision-Languageモデルが主流になっていくのかな、と思っていた矢先に画像だけの自己教師あり学習でこれだけの性能を持つモデルが発表されて驚きました。
当然このモデルのコードもオープンになっていますが、まだドキュメントが整備されていないようなので、整備され次第触ってみたいと思います。 github.com
論文読み Segment Anything
記事の概要

論文の概要
- この研究は画像のセグメンテーションにおける基盤モデルを構築することを目的としています。GPTのようにプロンプトエンジニアリングによって学習データに含まれない領域の画像に対しても動作することを期待しています。
- セグメンテーションでのプロンプトはどの物体を区分けするかの指示であり、物体上の点や物体を囲うボックス、あるいはテキストが考えられます。
- なおSAMのコードは公開されていますが(https://github.com/facebookresearch/segment-anything)、現時点ではtextによる機能はリリースされていないようです。(参考: Text prompt? · Issue #4 · facebookresearch/segment-anything · GitHub)
- デモではワンクリックでプロンプトなしに画像全体にセグメンテーションをかけることもできます。内部では画像全体にグリッド上に点を生成して、それをプロンプトとしてセグメンテーションを実行しているようです。
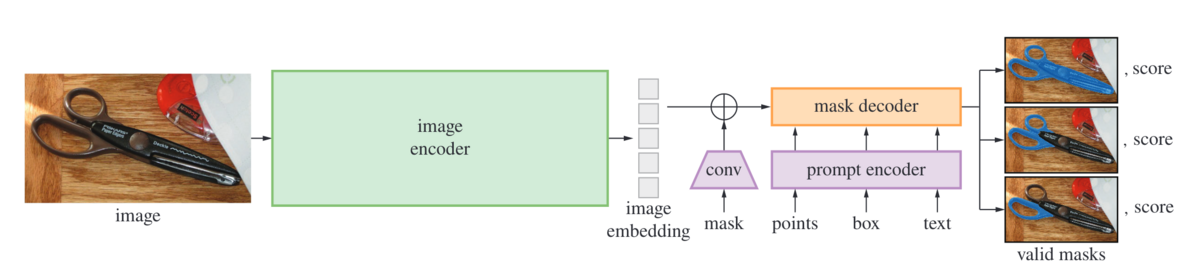
- SAMのアーキテクチャは以下のようになっており、画像をembeddingに変換するencoderと異なる種類のプロンプトを取り扱うprompt encoder、そしてそれらから物体の区分け情報であるmaskを出力するmask decoderに分かれています。image encoderの処理はやや重いですが、後段のモデルは軽いためwebブラウザでも動作するようです。
- 実際にデモを動かしてみると、画像読み込み時にembedding生成処理が入り、その後はシームレスに物体を切り出すことができます。
- 実際にデモを動かしてみると、画像読み込み時にembedding生成処理が入り、その後はシームレスに物体を切り出すことができます。
- 曖昧なプロンプトへの対応: 以下の右の例ではロゴの「Z」部分に点のプロンプトがありますが、壁面を指しているか、ロゴ全体なのかZだけなのか曖昧です。
- これに対応するため、SAMでは1つのマスクではなく複数のマスク(デフォルトでは3つ)を出力しています。なお学習時は最もロスが小さい出力に関してのみback-propagateしているようです。

- 複数プロンプトがある場合は曖昧さが少ないと考え、1つのマスクだけを出力するようになっています。デモも点プロンプトが1つの時の場合のみMulti-maskが使用可能になっています。
- これに対応するため、SAMでは1つのマスクではなく複数のマスク(デフォルトでは3つ)を出力しています。なお学習時は最もロスが小さい出力に関してのみback-propagateしているようです。
- GPT同様、基盤モデルを作るには大量のデータが必要です。ただテキストデータと違い、アノテーション付きの画像なんてweb上にはほとんどありません。この研究では人力によるアノテーションに加え、SAMを利用してアノテーション作成→モデルの更新というサイクルによってデータ量を増やすというアプローチを取っています。
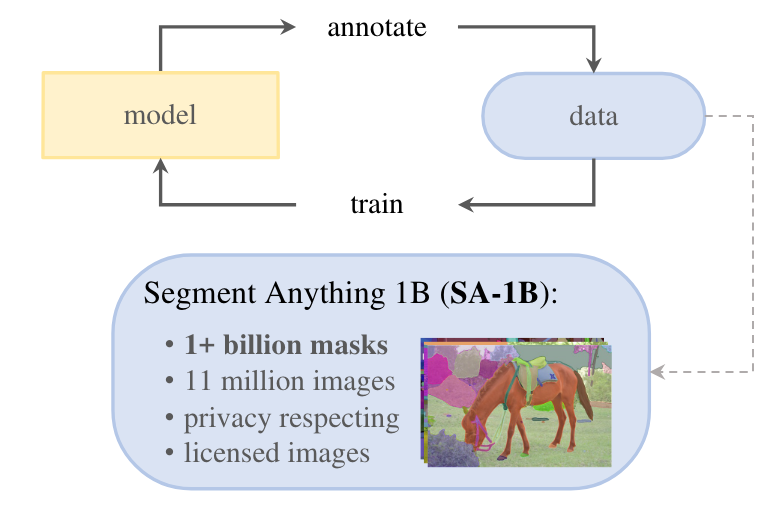
- このデータセットも公開されており、論文中には取得した国毎のデータ量や、性別や肌色によるSAMの精度のような公平性に関する情報も記載されています。
- 以下の画像は追加の学習なし(Zero-Shot)での物体のエッジ検出タスクの結果です。このデータセット(BSDS500)で学習していないにも関わらずground truthよりも詳細なエッジ情報が出力されています。(その影響で数字上ではPrecisionが低くなってしまうようです。)

感想
- GPTのような基盤モデルを参考にして、セグメンテーションの基盤モデルに必要なタスク、モデル、データを構築していくというプロセスが記されており、研究の進め方もとても参考になる論文でした。誰でもすぐに試せるようにデモも用意されているため、多くの人に使われるモデルになりそうです。
- 論文中でも触れられていますが、GPTやCLIPのような有名な基盤モデルに比べるとSAMは用途が限定されています。個人的にも既存の基盤モデルとは少し違う印象を受けましたが、プロンプトエンジニアリングの概念をコンピュータビジョンに持ってくるというアイデアは面白いので、さらなる研究を期待します。
- モデルの詳細も理解しようと思いましたが色々な論文のテクニックが使われていて思ったより難しそうなので力尽きてしまいました…せっかくコードは公開されているので、またリベンジしたいところです。
ChatGPTに関する有用な記事のまとめ(2023/4/7)
記事の概要
リンク集
ChatGPTを学ぶ意義
- 今、ChatGPTの使い方を学ぶのは、効率が悪い?
- 情報が氾濫していると落ち着くまで待った方が良いのではと思うことがあります。それでも今学んだ方が良い理由について述べられています。
- 『いまのうちにChatGPTの全体像を把握しておいて、新バージョンが出るたびに自分の知識とスキルもバージョンアップしていけば、やがてChatGPTの仕様や使い方が複雑で高度になったときも、その全体像を感覚的に把握できるのではないでしょうか。』note.com
- GPT-4時代のエンジニアの生存戦略
- この記事ではエンジニアがChatGPTとどう付き合っていくべきかを書かれています。
- 『AIがカバーできる領域が広がったことにより、エンジニアには「コードを書くこと」自体では無く、「ビジネスサイドが実現したいこと」を実現する能力がより強く求められるようになります。』qiita.com
プロンプトの作り方
- あなたの仕事が劇的に変わる!? チャットAI使いこなし最前線
- ChatGPTは馬鹿じゃない! 真の実力を解放するプロンプトエンジニアリングの最前線
- 例題付きでChain-of Thoughtなどのプロンプトエンジニアリング手法が解説されていて面白いです。zenn.dev
活用例
- ChatGPT4 本格RPG「チャット転生 〜 死んだはずの幼馴染が異世界で勇者になっていた件」(体験版)
- ChatGPTでブレストをすると、無限にできてヤバイという話
- ChatGPTを検索変わりに試す人が多いと思いますが、正解のある質問よりもこういうアイデアを発散させる使い方の方が今は向いていそうです。kensuu.com
- 新入社員のみんな、「ChatGPT×Python」で鬼にならないか?
- AIにコードまるごと解説してもらうと、界王拳100倍すぎる件
- コードを読む時にも使えます。仕事で使うことはまだ認められていませんが、コードレビューが捗りそうなので早く使えるようになってほしいです。note.com
- ChatGPTにマインドマップを作ってもらったら理解速度が爆速になる件
- PlantUML形式で出力してもらえば図も作れる。これは色々と応用が効きそうです。note.com
感想
- 以前以下の記事で紹介したコードをChatGPTで作れるか試してみましたが普通にできました。失礼ながらカーリルの図書館APIというそこまで有名ではない日本のAPI仕様を、ChatGPTは完璧に理解しており、この程度の実装ができることは最早なんの価値もないことを悟りました。aburaku.hatenablog.com
- 今後のキャリアについても割と悩みましたが、まずはもっとChatGPTを使い込んでみないと何ができて何ができないかがわからない、ということで遅ればせながら最新情報を追い始めています。
- 自分の仕事が無価値になってしまうのではないかという漠然とした不安もありますが、逆に使いこなすことで今までできなかったことが自分にも出来るようになればと前向きに捉えて今後も色々試していこうと思います。
Waymoの行動予測モデル(Waymo at CoRL 2022 | Behavior Models for Autonomous Driving)
記事の概要
- 2022年のConference on Robot Learningという学会でのWaymoの研究部門の責任者であるDrago Anguelov氏の講演内容をまとめます。
- 動画中で多くの論文が紹介されていますが、本記事では概要にとどめて詳細な解説は別の記事に譲ります。また、本講演は行動予測モデルと自動運転車のプランニングを含みますが、本記事では前者のみを取り扱いますのでご了承ください。
- 既に一部地域で自動運転サービスを開始しており、その様子が動画の最初の方にありますので視聴をおすすめします。
動画の概要
- 自動運転で特に難しいドメイン固有の問題を"Diverse and Complex Multi-agent Interactions"(多様で複雑な複数のエージェントの相互作用)と捉えており、彼らはこれまでの走行で得てきた大量のデータを用いて解決しようと考えています。
Behavior Prediction
Scalable Modeling Architectures
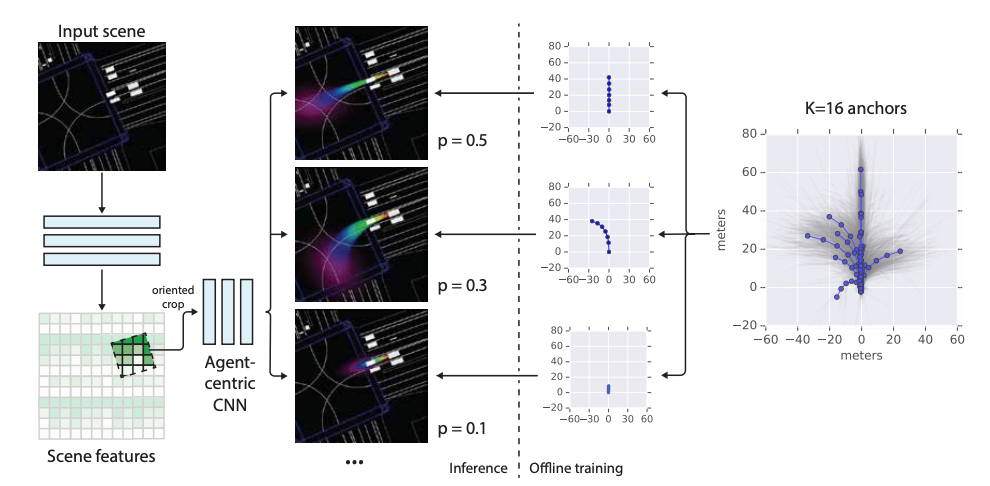
- 以下の論文ではレーンや自動車を線で描画したラスター形式の入力でCNNを用いて各agentの行動を予測しています。事前に16通りの行動パターンを容易しておき、それぞれに対する確率を出力しているようです。
- ラスター形式はより精度の高い入力にするとその分計算量が増えること、またCNNでは長距離の依存関係を考慮するのが難しいという課題がありました。そのため以下の論文ではtrajectoryや地図情報をベクトル形式で表現し、グラフネットワークを用いるという手法をとっています。
- その後の様々な改良を加えたモデルが以下の論文です。性能は良いものの、モデルが細かいブロックに分割されており、それぞれのドメインに対してエキスパートが必要な複雑な構造になっています。
- シンプルで精度/latencyのトレードオフの調整が簡単で、かつスケーラブルなモデルを目指した研究が2022年に発表された以下の論文です。Transformerをベースにしたシンプルなモデルになっています。


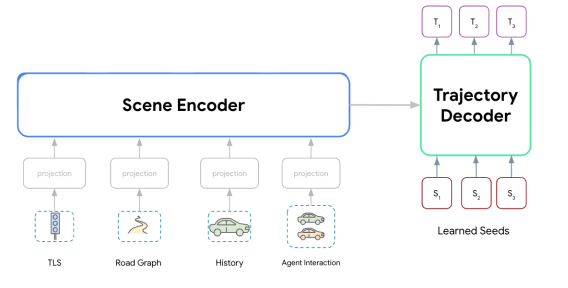
Modeling Interactions
- これまではモデルのアーキテクチャに着目してきました。モデルの出力は各agentの確率的に表現されたtrajectoryですが、これらの出力からagent同士が衝突するかどうかをどのように考慮すれば良いかというのが次の問題です。
- 2022年に発表された以下の論文では、agentのペアの相互作用を考慮したend to endモデルを提案しています。
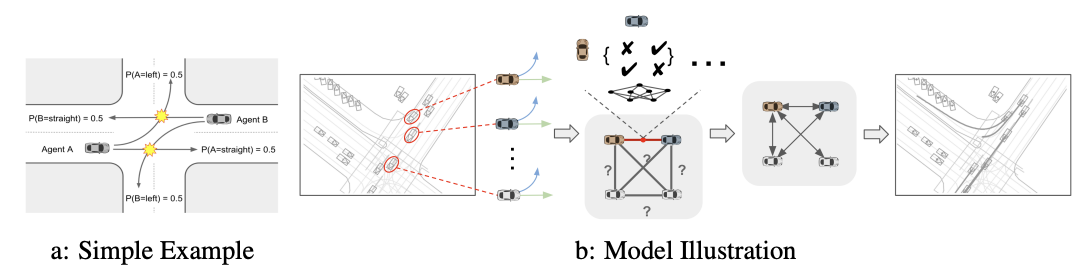
感想
- とても情報量の多い講演でした。今回は自分の興味があるbehavior modelsを追うだけで精一杯ですが、また機会があれば後半の方もまとめたいと思います。
- 最新の研究だけでなく、これまでの研究も紹介されていたのがとても良かったです。そして最後はTransformerに行き着くというのも面白い。本当にあらゆる分野で使われていますね…
論文読み A ConvNet for the 2020s
記事の概要
論文の概要
- 著者はSwin Transformerのshifted windowがConvNetに類似していることから着想を得て、逆にSwin Transformer(Swint-T)に使われるテクニックをConvNetへ輸入したConvNeXtsを提案しています。
- 結果は以下の通りで、新たテクニックを導入するごとに性能が改善され、最終的にはSwin-Tに匹敵する(ImageNet-1Kでの)性能になることが示されています。論文では物体検出やセマンティックセグメンテーションでも同様の性能であることが示されています。

導入されたテクニック
Training Techniques
- 以下のようなモダンな学習技術を使うことで、精度を76.1%→78.8%を向上させています。
- optimizerにAdamWを使用、学習エポックを90→300に増加
- Data augumentationにMixup、Cutmix、RandAugment、Random Erasingを使用。
- regularizationにStochastic Depth、Label Smoothingを使用。
Macro Design
- stage毎のResNet blockの繰り返しをSwin-Tに習って1:1:3:1の比率に変更。
- また先頭のレイヤーをSwin-Tのパッチ化に合わせて4×4、stride4の畳み込みに変更。

ResNeXt-ify
Inverted Bottleneck
- MobileNetV2でも使われるInverted Bottleneckを採用。
Large Kernel Sizes
Micro Design
- その他以下のような変更が加えられています。いずれもSwin-Tで使われる手法です。
- 活性化関数をReLU→GeLUに変更。活性化関数はブロック毎に1つだけに。
- normalizationも減らしてBatchからLayer Normalizationに変更。
- ステージ毎にダウンサンプリング用の2×2, stride2のconvを追加。

感想
- Swin-Tを参照しながら、それに使われているConvNetの最新手法をふんだんに利用した研究になっています。まだ自分も全てを網羅できていませんが、最新手法をキャッチアップする上でも勉強になる論文でした。
- 「巨大なTransformerに大量のデータを突っ込めば良い」というのが私のイメージする最近の深層学習のトレンドですが、面白くないし巨大企業に力が集中するのも不健全と思います。なので、本論文のようなアーキテクチャを検討する研究は応援したくなります。
- GPT-4のような自然言語と画像を組み合わせるモデルにはTransformerが使われ続けると思いますが、CV単独ではViTでもSelf-Attentionは必須ではないという研究もありますので、今後どのようなアーキテクチャに落ち着くのか注目したいです。
論文読み Image as a Foreign Language: BEIT Pretraining for All Vision and Vision-Language Tasks
論文の概要
- 論文の1ページ目から目を引く結果が掲載されています。Vision, Vision-Languageのあらゆるタスクで既存の基盤モデルの性能を上回っています。

- モデルの構造自体は別論文で提案されたMoME transformerというものです。self-attentionが共通になっており、その後のMLPがVision、Language、Vision-Languageそれぞれで独立した構造になっています。

- 元論文では画像とテキストで異なるタスクで学習していたのに対し、本論文ではtokenの一部をマスクしてマスク前のtokenを復元するという共通タスクで学習しているのが特徴です。
- 基盤モデルということで大量のパラメータを大量のデータで学習しています。maskの復元という1つのタスクに取り組むことが、スケールアップを容易にしているようです。

感想
- GPTもそうですが、巨大なtransformerを大量のデータとmaskの復元問題で学習するというのが今の主流のようです。機械学習自体がそういうものだから仕方ないですが、大量のリソースを持つ大企業による寡占が今後さらに進行しそうですね…
読書記録 Optunaによるブラックボックス最適化

本から学んだこと
ブラックボックス最適化
Optunaの概要
- 目的関数の1回の評価をtrial、一連の最適化プロセスをstudyと呼ぶ。Studyオブジェクトは全てのtrial情報を持っているので最良の試行以外の結果も取り出せる。
- Optunaは複数の指標を持つ多目的最適化問題にも対応している。パレートフロントによる可視化に対応。多目的最適化は「複数の目的のトレードオフを探索し、最後のパラメータの選択は人間が行う」という状況で活躍する。
- 探索空間を絞るには条件付き最適化や枝刈り(pruning)がある。また、ドメイン知識がない場合はRandomSamplerで探索を行い、ハイパーパラメータの重要度の可視化によって手動で探索空間を絞っていくのも有効。
- 探索点を手動で指定できる(study.enqueue_trial)。事前に有望なパラメータがわかっていたりする場合は有効。CmaEsSamplerはWarm Startに対応しており、以前の探索結果を再利用できる。
最適化の仕組み
- Optunaのsamplerは独立サンプリングと同時サンプリングの組み合わせで柔軟なインターフェースを実現している。Trialオブジェクト作成時に過去の試行を元に同時サンプリングを行い、次に目的関数呼び出し時にサジェストAPIでパラメータを取得する。この時同時サンプリングされていないパラメータがあれば独立サンプリングが行われる。
- TPESamplerはデフォルトで独立サンプリングのみを行うため、同時サンプリングをしたい場合は引数で指定する必要あり。
- 探索点の選択は探索と活用のトレードオフで、各samplerはそれぞれ独自の方法でこれに取り組む。それぞれのsamplerの特徴はこちらのドキュメントにまとめられています。optuna.samplers — Optuna 3.1.0 documentation
- 基本はデフォルトのTPESamplerで良いと思いますが、1000を超えるような多くのtrialを実行する場合は進化計算によるCmaEsSamplerの方が適している。