論文読み Segment Anything
記事の概要

論文の概要
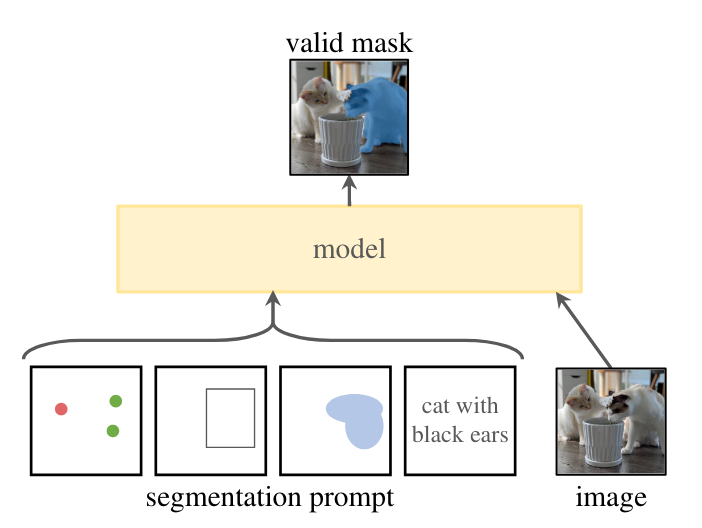
- この研究は画像のセグメンテーションにおける基盤モデルを構築することを目的としています。GPTのようにプロンプトエンジニアリングによって学習データに含まれない領域の画像に対しても動作することを期待しています。
- セグメンテーションでのプロンプトはどの物体を区分けするかの指示であり、物体上の点や物体を囲うボックス、あるいはテキストが考えられます。
- なおSAMのコードは公開されていますが(https://github.com/facebookresearch/segment-anything)、現時点ではtextによる機能はリリースされていないようです。(参考: Text prompt? · Issue #4 · facebookresearch/segment-anything · GitHub)
- デモではワンクリックでプロンプトなしに画像全体にセグメンテーションをかけることもできます。内部では画像全体にグリッド上に点を生成して、それをプロンプトとしてセグメンテーションを実行しているようです。
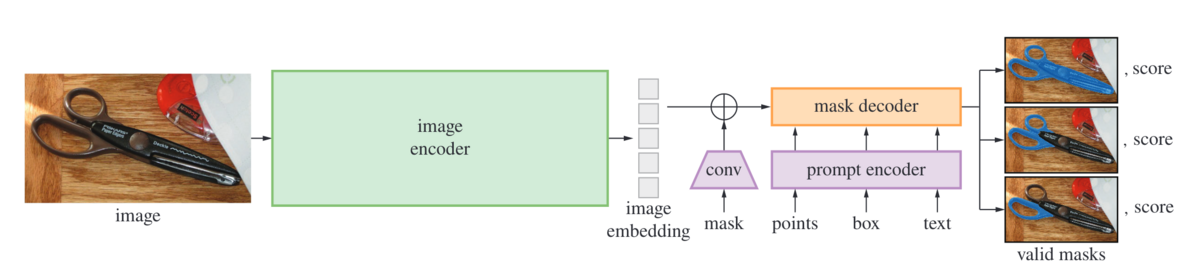
- SAMのアーキテクチャは以下のようになっており、画像をembeddingに変換するencoderと異なる種類のプロンプトを取り扱うprompt encoder、そしてそれらから物体の区分け情報であるmaskを出力するmask decoderに分かれています。image encoderの処理はやや重いですが、後段のモデルは軽いためwebブラウザでも動作するようです。
- 実際にデモを動かしてみると、画像読み込み時にembedding生成処理が入り、その後はシームレスに物体を切り出すことができます。
- 実際にデモを動かしてみると、画像読み込み時にembedding生成処理が入り、その後はシームレスに物体を切り出すことができます。
- 曖昧なプロンプトへの対応: 以下の右の例ではロゴの「Z」部分に点のプロンプトがありますが、壁面を指しているか、ロゴ全体なのかZだけなのか曖昧です。
- これに対応するため、SAMでは1つのマスクではなく複数のマスク(デフォルトでは3つ)を出力しています。なお学習時は最もロスが小さい出力に関してのみback-propagateしているようです。

- 複数プロンプトがある場合は曖昧さが少ないと考え、1つのマスクだけを出力するようになっています。デモも点プロンプトが1つの時の場合のみMulti-maskが使用可能になっています。
- これに対応するため、SAMでは1つのマスクではなく複数のマスク(デフォルトでは3つ)を出力しています。なお学習時は最もロスが小さい出力に関してのみback-propagateしているようです。
- GPT同様、基盤モデルを作るには大量のデータが必要です。ただテキストデータと違い、アノテーション付きの画像なんてweb上にはほとんどありません。この研究では人力によるアノテーションに加え、SAMを利用してアノテーション作成→モデルの更新というサイクルによってデータ量を増やすというアプローチを取っています。
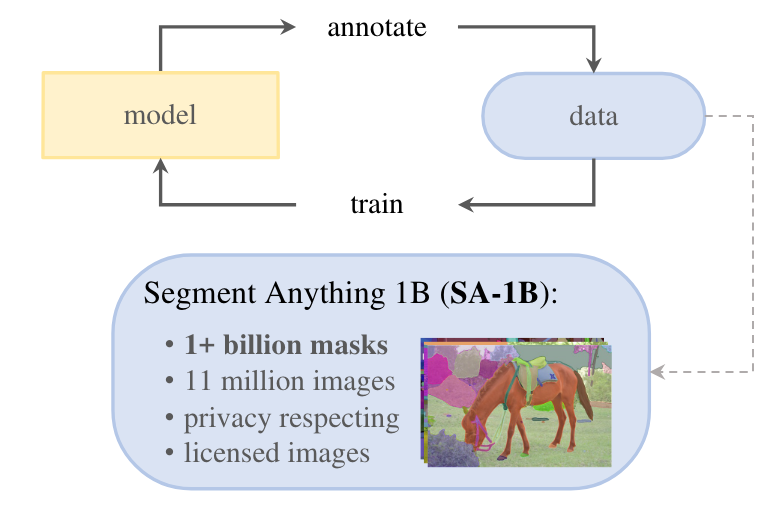
- このデータセットも公開されており、論文中には取得した国毎のデータ量や、性別や肌色によるSAMの精度のような公平性に関する情報も記載されています。
- 以下の画像は追加の学習なし(Zero-Shot)での物体のエッジ検出タスクの結果です。このデータセット(BSDS500)で学習していないにも関わらずground truthよりも詳細なエッジ情報が出力されています。(その影響で数字上ではPrecisionが低くなってしまうようです。)

感想
- GPTのような基盤モデルを参考にして、セグメンテーションの基盤モデルに必要なタスク、モデル、データを構築していくというプロセスが記されており、研究の進め方もとても参考になる論文でした。誰でもすぐに試せるようにデモも用意されているため、多くの人に使われるモデルになりそうです。
- 論文中でも触れられていますが、GPTやCLIPのような有名な基盤モデルに比べるとSAMは用途が限定されています。個人的にも既存の基盤モデルとは少し違う印象を受けましたが、プロンプトエンジニアリングの概念をコンピュータビジョンに持ってくるというアイデアは面白いので、さらなる研究を期待します。
- モデルの詳細も理解しようと思いましたが色々な論文のテクニックが使われていて思ったより難しそうなので力尽きてしまいました…せっかくコードは公開されているので、またリベンジしたいところです。