CoordConv: 座標に関わるCNNの弱点を克服する拡張
今回は『An intriguing failing of convolutional neural networks and the CoordConv solution』という論文を紹介します。 この論文ではCNNが苦手とする画像上の座標情報に関するタスク性能を向上するCoordConvという構造を提案しています。
arxiv.org
PyTorch版の実装: https://github.com/mkocabas/CoordConv-pytorch
◆一言サマリー
CNNは座標⇔画像の変換が苦手なので、座標情報を入力に追加してあげると性能が向上する。
論文内容
CNNが苦手な問題
we expose and analyze a generic inability of CNNs to transform spatial representations between two different types: from a dense Cartesian representation to a sparse, pixel-based representation or in the opposite direction.
要するにCNNはx,y座標と画像のピクセル表現間の変換を苦手とするようです。画像上の物体の位置をbounding boxの座標として出力する物体検出タスクが一例です。
 また本論文では性能比較のために簡単なタスクをいくつか定義しています。最もシンプルなものは画像の通りx, y座標情報を入力にしてどのピクセルに対応しているかを分類する問題です。(ここで分類するクラス数はピクセル数と同じ)
また本論文では性能比較のために簡単なタスクをいくつか定義しています。最もシンプルなものは画像の通りx, y座標情報を入力にしてどのピクセルに対応しているかを分類する問題です。(ここで分類するクラス数はピクセル数と同じ)
また、逆に黒地に白いポイントが1つの画像を入力にして、対応するx, y座標を推論する回帰タスクでも評価されています。
CoordConv layer
 CoordConv layerは上図のように従来の畳み込みlayerの拡張です。CNNに座標情報の弱点があるということで、シンプルに座標情報を入力に追加する形です。
CoordConv layerは上図のように従来の畳み込みlayerの拡張です。CNNに座標情報の弱点があるということで、シンプルに座標情報を入力に追加する形です。
具体的にはi coordinateチャンネルは各列がx座標の値を持ち、j coordinateチャンネルは各行がy座標の値を持ちます。(実際にはこれらの値は[-1, 1]の範囲に正規化されるようです)
i,j coordinateはすべて固定値で、これらと元の入力が統合された行列が後段の畳み込み層に入力されます。そのため、パラメータの増加量は入力チャンネルが2増えた分だけです。
性能
以下のグラフでは上述のx, y座標を入力にして対応するピクセルを予測する分類問題の結果です。単なるCNNとCoordConvを追加したモデルとで比較すると、精度も学習にかかる時間も段違いです。またパラメータ数もCNNが200kに対してCoordConvありでは7.5kで済んでいます。
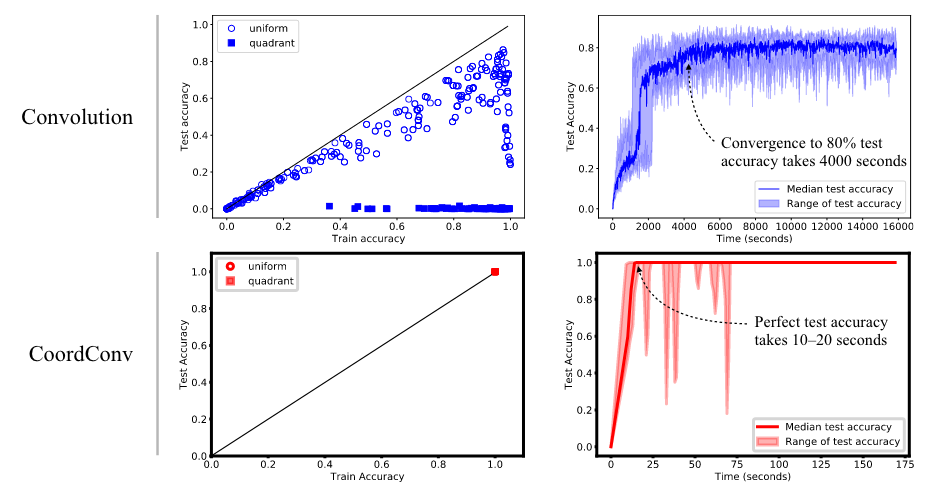
◯で示されるuniformのグラフはtrain/testデータの分割をx, y座標面の全体からランダムに行ったものです。CNNではこのようなデータに対してもaccuracyが86%程度にしか過ぎないため、著者は以下のようにCNNにはこのタスクが困難であると結論付けています。なお逆の画像→座標の回帰タスクにおいてもCoordConvの優位性が示されています。
learning a smooth function from (x, y) to one-hot pixel is difficult for convolutional networks, even when trained with supervision, and even when supervision is provided on all sides.
また、実験用のデータセット以外の実践的なタスクでもCoordConvとCNNの比較が行われています。
- 座標情報が関係ないImageNet ClassificationではResNet-50にCoordConvを追加したところaccuracyが0.04%改善。これは優位な差があるとは言えませんが、CoordConvはClassificationの邪魔をしないことがわかります。座標に関係の無いタスクではi, j coordinateが影響を持たないように学習されているためと思われます。
- 座標を出力する物体検出ではMNISTの数字画像をランダムに入力画像上に配置した問題において、R-CNNのIOUをCoordConvで24%改善しています。
感想
- CNNにそんな弱点があることなんて考えたこともありませんでした…この論文は2018年に発表されていたのに不勉強でした。
- CoordConvは実装自体は容易で、処理速度にも大きな影響を与えないので物体検出など出力に画像上の座標情報を含むタスクをする場合はとりあえず試してみる価値がありそうです。