【Waabi CVPR 24 Tutorial】 Motion Forecasting
カナダのトラック自動運転のスタートアップ、WaabiのMotion Forecastingチュートリアルから一部を抜粋してまとめました。本文中のスライドは動画をキャプチャしたものです。 www.youtube.com
内容の抜粋
認識と予測
- 従来予測タスクは認識とプランニングの間に位置していました。そのため認識によって得られた過去のトラジェクトリーと地図情報をNNに入力して未来のトラジェクトリーを得るというのが定番の形です。
- 本発表では認識と予測を一つのモデルに統合することの優位性を説いています。このタスクでは時系列のセンサーデータをNNに入力して、認識と予測を一度に行っています。
- 従来の認識側のノイズが予測に蓄積されたり、逆に情報が失われる可能性がある点を克服するとともに、計算量の点でも効率的な点で優位性があるようです。

リッチな特徴を得る
- 予測の入力には過去の情報は必要不可欠です。やはり従来は認識とトラッキングでトラジェクトリーを得ていましたが、本発表ではLiDARデータから直接特徴量を抽出する手法を説明しています。センサーデータにはどこが見えていないかというような情報も含まれているため、より多くの情報が含まれています。

予測タスクの立て方
- エージェント同士は互いに影響を及ぼすため、それぞれの未来の分布を独立して表現(marginal distribution)するよりも合わせて表現(joint distribution)した方が良さそうです。
以下のスライドのように予測結果が3通りある場合、エージェント毎に一番良い予測に対して学習をするとmarginal distributionが得られますが、これをシーン単位で一番良い予測に対して学習をすることでjoint distributionを得られるらしいです。

予測の出力形式として、トラジェクトリー以外に未来のセンサーデータそのものやOccupancyが紹介されています。特にOccupancyはトラジェクトリーとセンサーデータの良いとこどりと評価されています。
- トラジェクトリーよりも柔軟かつ、Lidarデータを使えば物体に対してアノテーションをする必要がないため教師なし学習も可能という点も評価されています。

感想
- 予測について従来型のトラジェクトリーをベースにしたモデルしか知らなかったので、思った以上にバリエーションが多くて驚きました。
- 予測はどうしても100%正しい結果を得られないため、その不確定性をどう扱うかという点に特に注目して今後は論文を読んでいこうと思います。
読書記録『続ける思考』: 習慣作り本で一番のオススメ
ブックデザイナー井上新八氏による『続ける思考』という本を紹介します。
私は昨年習慣作りに関する本を何冊か読みましたが、個人的に本書が一番心に残りましたのでおすすめします。

◆一言サマリー
効率よりも目的よりも、とにかく続けることを重視しよう!続けることで「好き」が見つかる。
参考になった記述
わたしは「続けること」それ自体が好きだったんです。 続けるためにいろいろ工夫すること、続けることを増やすこと、これ全部、趣味だったって気がついた。 「趣味、継続。」
習慣本を既に散々読んだ私がこの本を読もうとしたきっかけは、本の帯に「継続が趣味になる」という旨が書かれていたことです。
ほぼ無趣味の自分にとって、「継続」というやや抽象的なことも趣味になりうるのかと目から鱗が落ちました。
ラクに続けるコツは、週1日やる、週2日やるではない。 週7日やる、これなのだ。 じつはこの本で読むべきところは、この1行だけ。これが絶対の最強法則。
元も子もない主張ではありますが、これはその通りだと思います。
週に数回だけだと始めるのにエネルギーが必要なんですよね…週5以上やる場合は「基本的にやる」という気持ちになっているので始めるのが楽だったりします。
「うまくなる」「よくなる」ファーストの考え方をやめてもいいんじゃないかと思う。 「正しい努力」という考えを捨てて、「ただ続ける」ことをまずは意識する。 いわば、「正しい継続」だ。
効率化はもちろん悪いことではないけど、それでしんどくなって止めてしまっては元も子もないです。
なかなか成果が出ない時、始めたは良いけどすぐに面白さが理解できない時は続けるのを止めてしまいがちです。私も多くの趣味の種をこれで潰してきました。そういう時は「ただ続ける」の精神が大切になってきそうです。
「なんのためにこれやるの?」それを考えはじめると思考が止まる。 理由なんかわからなくていい。 「なんのため」ではなく「なんとなく」。 もっとこの感覚を大事にしてもいいと思う。
継続することの目的まで考えないというのは初めて出会う考え方でした。
やってみて初めて面白さがわかることが多いと思います。目的も重要ですが、それに縛られると何かを始めるハードルが高くなってしまうのは考えものですね。
「時間をかける」ということは、「続ける」ことの先にある。 きっとわたしは時間をかければ「好き」を見つけられることに気づいたのだ。 だから「続ける」ことが「好き」になったのだと思う。
「好き」だから続けられる、だから好きなものを見つけないと、と自分は思っていました。
ここでは逆に続けたから、時間をかけたから何かを好きになれるという逆転の発想が書かれています。なかなか熱中できるものが見つからない自分に勇気を与えてくれる一節でした。
「早く行きたければ、ひとりで進め。遠くまで行きたければ、みんなで進め」 アフリカのことわざだというこの言葉が、わたしはあまり好きじゃない。 ひとりの力をなめるな! ひとりでだって思ったより遠くに行けるぞ! そう言いたい気持ちでこの本を書いた。
これが本書の裏テーマらしいです。本文中も一人で映画を制作した人のエピソードもありました。
自分も誰かを頼りにするよりも、一人でコツコツやることの方が好きなタイプなのでこれもまた勇気づけられる言葉でした。
感想
- 習慣作りの鍵はとにかくハードルを下げること、というのは多くの本で既に語られていますが、本書ではさらに「効率」や「目的」までも廃して徹底的に継続のハードルを下げています。お陰で気楽に何かを始めてみようかという気分になりました。
- 本記事では触れませんでしたが、本書には継続するための仕組み作りについても書かれています。気になる方はぜひ手にとって見てください。
CoordConv: 座標に関わるCNNの弱点を克服する拡張
今回は『An intriguing failing of convolutional neural networks and the CoordConv solution』という論文を紹介します。 この論文ではCNNが苦手とする画像上の座標情報に関するタスク性能を向上するCoordConvという構造を提案しています。
arxiv.org
PyTorch版の実装: https://github.com/mkocabas/CoordConv-pytorch
◆一言サマリー
CNNは座標⇔画像の変換が苦手なので、座標情報を入力に追加してあげると性能が向上する。
論文内容
CNNが苦手な問題
we expose and analyze a generic inability of CNNs to transform spatial representations between two different types: from a dense Cartesian representation to a sparse, pixel-based representation or in the opposite direction.
要するにCNNはx,y座標と画像のピクセル表現間の変換を苦手とするようです。画像上の物体の位置をbounding boxの座標として出力する物体検出タスクが一例です。
 また本論文では性能比較のために簡単なタスクをいくつか定義しています。最もシンプルなものは画像の通りx, y座標情報を入力にしてどのピクセルに対応しているかを分類する問題です。(ここで分類するクラス数はピクセル数と同じ)
また本論文では性能比較のために簡単なタスクをいくつか定義しています。最もシンプルなものは画像の通りx, y座標情報を入力にしてどのピクセルに対応しているかを分類する問題です。(ここで分類するクラス数はピクセル数と同じ)
また、逆に黒地に白いポイントが1つの画像を入力にして、対応するx, y座標を推論する回帰タスクでも評価されています。
CoordConv layer
 CoordConv layerは上図のように従来の畳み込みlayerの拡張です。CNNに座標情報の弱点があるということで、シンプルに座標情報を入力に追加する形です。
CoordConv layerは上図のように従来の畳み込みlayerの拡張です。CNNに座標情報の弱点があるということで、シンプルに座標情報を入力に追加する形です。
具体的にはi coordinateチャンネルは各列がx座標の値を持ち、j coordinateチャンネルは各行がy座標の値を持ちます。(実際にはこれらの値は[-1, 1]の範囲に正規化されるようです)
i,j coordinateはすべて固定値で、これらと元の入力が統合された行列が後段の畳み込み層に入力されます。そのため、パラメータの増加量は入力チャンネルが2増えた分だけです。
性能
以下のグラフでは上述のx, y座標を入力にして対応するピクセルを予測する分類問題の結果です。単なるCNNとCoordConvを追加したモデルとで比較すると、精度も学習にかかる時間も段違いです。またパラメータ数もCNNが200kに対してCoordConvありでは7.5kで済んでいます。
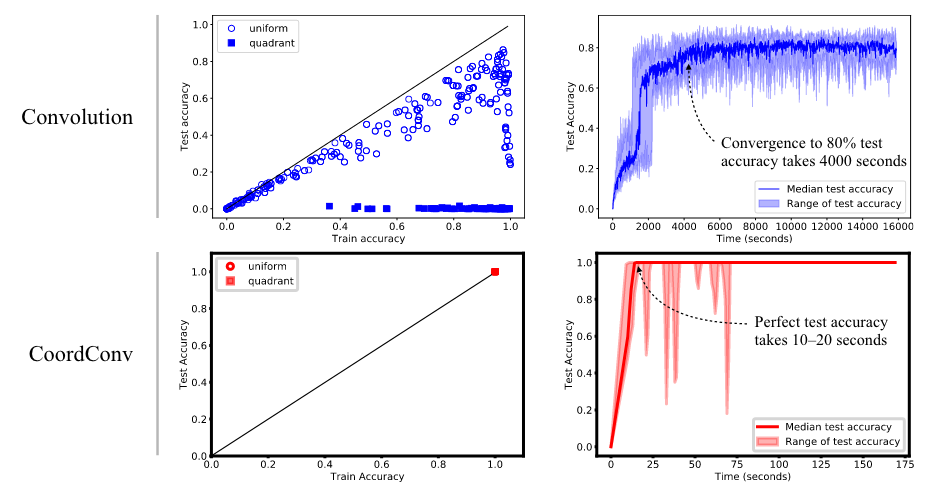
◯で示されるuniformのグラフはtrain/testデータの分割をx, y座標面の全体からランダムに行ったものです。CNNではこのようなデータに対してもaccuracyが86%程度にしか過ぎないため、著者は以下のようにCNNにはこのタスクが困難であると結論付けています。なお逆の画像→座標の回帰タスクにおいてもCoordConvの優位性が示されています。
learning a smooth function from (x, y) to one-hot pixel is difficult for convolutional networks, even when trained with supervision, and even when supervision is provided on all sides.
また、実験用のデータセット以外の実践的なタスクでもCoordConvとCNNの比較が行われています。
- 座標情報が関係ないImageNet ClassificationではResNet-50にCoordConvを追加したところaccuracyが0.04%改善。これは優位な差があるとは言えませんが、CoordConvはClassificationの邪魔をしないことがわかります。座標に関係の無いタスクではi, j coordinateが影響を持たないように学習されているためと思われます。
- 座標を出力する物体検出ではMNISTの数字画像をランダムに入力画像上に配置した問題において、R-CNNのIOUをCoordConvで24%改善しています。
感想
- CNNにそんな弱点があることなんて考えたこともありませんでした…この論文は2018年に発表されていたのに不勉強でした。
- CoordConvは実装自体は容易で、処理速度にも大きな影響を与えないので物体検出など出力に画像上の座標情報を含むタスクをする場合はとりあえず試してみる価値がありそうです。
『世界一流エンジニアの思考法』を読んで生産性を上げることを考えた

米マイクロソフトでAzure Functionsの開発に携わる牛尾剛氏による『世界一流エンジニアの思考法』を読みました。
本書では著者が世界最高峰のテック企業のエンジニアとして活躍するために、優秀な同僚達から学んだ仕事への取り組み方が書かれています。
")
私もエンジニアとして生産性を上げようと意識はしていますが、かえって努力が空回りして糧にならない失敗をしたり、残業が増えたりするような悪循環に陥っていました。
本書を読んで自分のどの考え方に問題があったのか見通しがついたので、その点を中心に感想をまとめました。
学んだこと
早く成果を出そうと頑張ることが生産性を下げることがある
目の前の仕事を早く終わらせようとして非効率的なことをしてしまうことがあります。本書では具体的に以下のような行動が挙げられています。
- バグの特定のためにすぐ手を動かして試行錯誤をする→時間がかかる割りには新しい知識を得ることがない。
- プログラミングでわからないことをググって出てきたものを使う→頭に残らないので何度も同じことを検索する。
試行錯誤もググることもエンジニアとして必要なこと、何ならこれを習慣づけられて初めて一端のエンジニアだとも思っていました。
それは間違っていないと思いますが、これらに頼りすぎると自分の生産性を上げることを阻害する可能性があるため注意が必要です。
どんなに頭のいい人でも理解には時間がかかる
著者の優秀な同僚でも何かを理解するには時間をかけて繰り返しを必要としています。
理解が曖昧でも試行錯誤とgoogleの力でそれっぽいことは出来るが、生産性は上がらないし複雑な技術はお手上げです。
著者は時間をかけて理解をする取り組みとして以下のものを挙げています。
- LeetCodeの一番簡単なレベルからプログラミングを学びなおす。
- 業務中でもミーティングなどで理解ができないことがあれば、後で時間をかけてでも理解に努める。
- 新しく学んだことはブログに書く。その際サンプルコードそのままではなく自分なりに変えてみる。
コードの理解をしていればデバッグ時も試行錯誤をする前に、仮説を立てて問題に当たりをつけることで試行を減らすことができます。
自分にとって難しすぎると感じることはたいてい脳の使い方が間違っている
また著者は生産性を上げるには脳みその負担を減らすことが重要で、しんどく感じる時はやり方を見直すべきと書いています。脳の負担を減らす取り組みは以下のようなことが書かれています(一部のみ抜粋)。
- コードを読む時は実装は見ずにインターフェースや構造の理解を優先する。
- 何も見ずにコーディングできることを増やしていく。
- メンタルモデルを頭の中に作り、頭だけで整理して記憶するする訓練をする。
まとめ
生産性を上げるためには地道に学習を継続して理解を積み重ねていくことが重要であることを再認識しました。今後は自分も時間をかけて理解することを実践していきます。
今後ChatGPTやgithub copilotなど便利なツールが広がっていくと思いますが、それが短期的な成果だけに繋がっていないか気をつけながら利用したいと思います。
※余談ですが、本記事冒頭の画像は最近ChatGPTから使えるようになったDALL-Eで生成したものです。
今回は自分が悩んでいる個人の生産性についてのみ触れましたが、本書ではコミュニケーションやチームビルディングに関してもページが割かれています。
多くのエンジニアにとって学びのある本だと思いますので、読んでみては如何でしょうか。私は著者のnoteも読んでみようと思います。
note.com
ByteTrack: シンプルな発想で性能と実効速度を向上したtrackingモデル
前回はreal-time性のあるMulti-object tracking (MOT)モデルとしてFairMOTを紹介しました。
aburaku.hatenablog.com
今回はシンプルな方法でさらに性能、実行速度共に大きく向上させたByteTrackを提案した論文、『ByteTrack: Multi-Object Tracking by Associating Every Detection Box』を紹介します。
arxiv.org
◆一言サマリー
confidenceの低い検出物体も捨てずに活用して、隠れている物体のtracking性能を向上!
論文の概要
既存研究の課題
多くのMOT研究では物体検出のconfidenceが低いboxを捨ててからtrackingを行います。
著者曰く低いconfidenceのboxは必ずしも誤検出とは限らず、occluded(他の物体の陰に隠れている)状態の可能性もあることもあり、これを見逃すことでかえって性能が悪化してしまうということです。
 上の図(a)において、時間が経つにつれて他の歩行者に隠れてconfidenceの値が0.9->0.4->0.1と減少している検出があります。
上の図(a)において、時間が経つにつれて他の歩行者に隠れてconfidenceの値が0.9->0.4->0.1と減少している検出があります。
(b)は一般的なtracking手法の結果で、confidenceの低い検出は捨ててしまうので当然trackingの対象外になります。
一方(c)のようにconfidenceの低い検出も含めてtrackingを行うことで、隠れてしまった物体のtrackingを継続できます。これが本論文で提案するBYTEアルゴリズムの基本的なアイデアです。
BYTE
BYTEは以下のように2段階でマッチングを行うアルゴリズムです。
物体検出のconfidenceが一定の値を超えるものと下回るものの2グループに分ける。
カルマンフィルタによって既存のtrackの次のframeでの位置を予測する。
confidenceの高い検出で1段目のマッチング。trackと検出の類似度計算はIoU(boxの重なり度合い)でもRe-Id特徴量のいずれでも可能。※Re-IDについてはFairMOTの記事を参照
confidenceの低い検出で2段目のマッチング。この時はIoUによる類似度計算を行う。confidenceの低い検出は隠れている場合もあるので、visualの情報に依存するRe-IDは適さない。
2段目でマッチングしなかった低いboxはbackgroundと見なして削除する。残ったtrackは30frame保存する。
性能比較

BYTEは既存のtracking手法と組み合わせられる柔軟な手法で、マッチングをBYTEにするだけで性能が向上しています。
また、論文タイトルになっているByteTrackは物体検出モデルとしてYOLOXを採用したもので、これが当時のSoTAになっています。
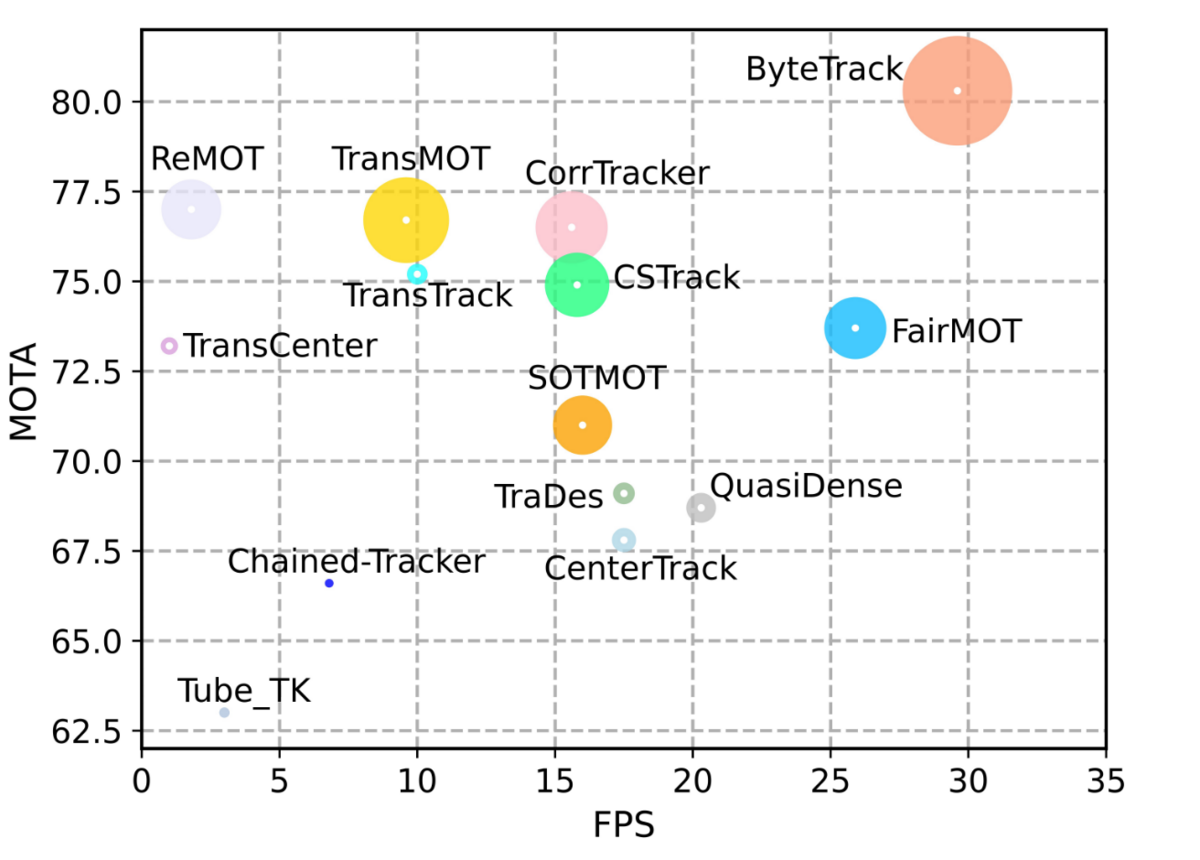
性能(縦軸)、実行速度(横軸)共に既存研究を圧倒していることがわかります。
感想
驚くほどシンプルな方法ながらも高い性能と実効速度を実現している手法です。
筆頭著者はFairMOTと同じ研究者で、やはりablation studyを丁寧に行っていてわかりやすい論文です。
同じ発想をした人はいたかもしれませんが、ここまで徹底的に研究をできた人がいなかったのだと思います。
ロボット工学で著名な金出教授の『素人発想、玄人実行』という考えを思い出されました。
")
物体検出と一体化したreal-timeなトラッキングモデルFairMOT
動画内で検出した物体が以降のフレームのどの物体に対応するかを解く問題はMulti-object tracking(MOT)と呼ばれ、近年ではこれにディープラーニングで取り組む研究も増えています。
今回はその中でもreal-time性の高いFairMOTを提案した論文「FairMOT: On the Fairness of Detection and Re-Identification in Multiple Object Tracking」を紹介します。
arxiv.org
論文の概要
既存研究の課題
- 既存研究の多くはdetectionモデル+associationモデルの2つの異なるモデルによるアプローチです。
- ここでassociationモデルは異なるフレーム間で検出されたbounding boxを対応付けするためのre-ID特徴量を抽出するものです。
- このアプローチは2つのモデル間で特徴をシェアできないため、推論速度が遅くリアルタイムの推論に向かないという欠点があります。

- 当然1つのモデルで物体検出とre-ID出力を行うモデルの研究もありますが、trackingの精度が明らかに落ちている問題があります。著者はその原因として以下の3点を挙げています。
- 多くのdetectionモデルで採用されるanchor boxはre-IDに適していない。anchorで物体検出→re-IDという順番では2つのタスクが競合した時に物体検出を優先してしまう。また混雑したシーンではanchorと物体が1対1対応しないことも問題になる。
- detectionとtrackingに必要な特徴量は異なる。trackingは同じclassの別個体を見分ける必要があるのでより細かな情報が必要だが、detectionでは同じclassなら別の個体でも近い特徴であるべき。
- 2つのタスクで特徴量の次元が異なる。re-IDは512や1024が使われ、一般的にdetectionよりも大きい。大きすぎるre-IDの次元は全体のバランスを損なう。
- FairMOTは上記の問題によって引き起こされるdetectionとre-IDタスク間の不公平を丁寧に取り除いた設計になっています。
FairMOTの構成
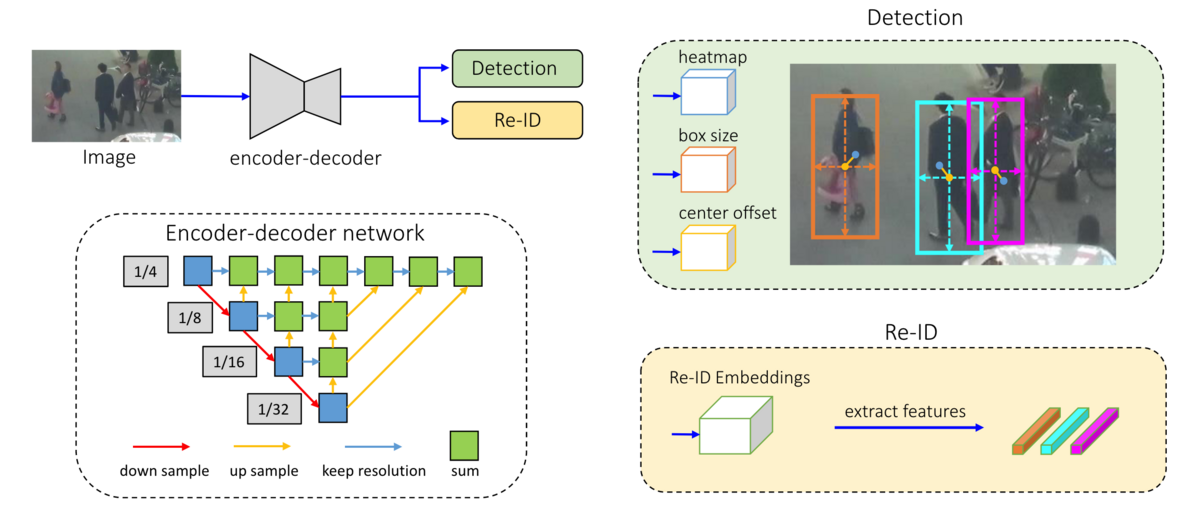
FairMOTの構成は上図のように画像から特徴量を抽出するBackBoneにDetectionとRe-IDブランチを並列に繋げたものです。
BackBone
- BackBoneにはDeep Layer Aggregation(DLA)と呼ばれる、異なるresolutionの特徴量を混ぜ合わせる構造が採用されています。backboneの出力は元のサイズから縦横それぞれ1/4になります。
Detectionブランチ
- 前述の通りanchorベースの物体検出モデルは向かないということで、anchorフリーモデルのCenterNetを採用しています。
- これは物体の中心点のheatmap、離散化誤差を補償するoffset、そして物体のサイズをそれぞれ出力するheadからなります。詳しくは以前記事にしていますので、そちらを参照ください。aburaku.hatenablog.com
Re-IDブランチ
- Re-IDの特徴量はheatmapの各点毎に128次元を持ちます。
- 学習データ内の全objectを分類する問題として学習を行います。loss計算時は物体中心点の特徴量だけが考慮されます。
- Re-ID lossとdetection lossは学習可能なパラメータによってバランスがとられます。(Uncertainty loss)
推論時の流れ
- まずはCenterNetと同様の流れでDetection結果を元にbounding boxを生成していきます。
- 具体的には3*3のmax poolingでheatmapの極大点を抽出(従来のNMSに相当)し、その中で閾値以上のconfidenceのものだけを残します。
- その後box sizeとoffsetからbboxを求め、また物体中心点のRe-id特徴量を抽出します。
- その後2段階のマッチング戦略で以前のフレームのbounding boxと検出されたbounding boxを紐づけます。
- 1st: Kalman filterで次のフレームでの位置を予測し、検出されたbox達とのMahalanobis距離を計算する。また、Re-id特徴量同士のcosine距離も求めてそれらの距離を係数を掛けて足し合わせた値でマッチング。
- 2nd: 残ったboxをIoUを元にマッチングする。そこでも残った新規検出boxを新しいtrackとみなし、マッチしなかった過去のtrackは30frame保存する。
性能比較
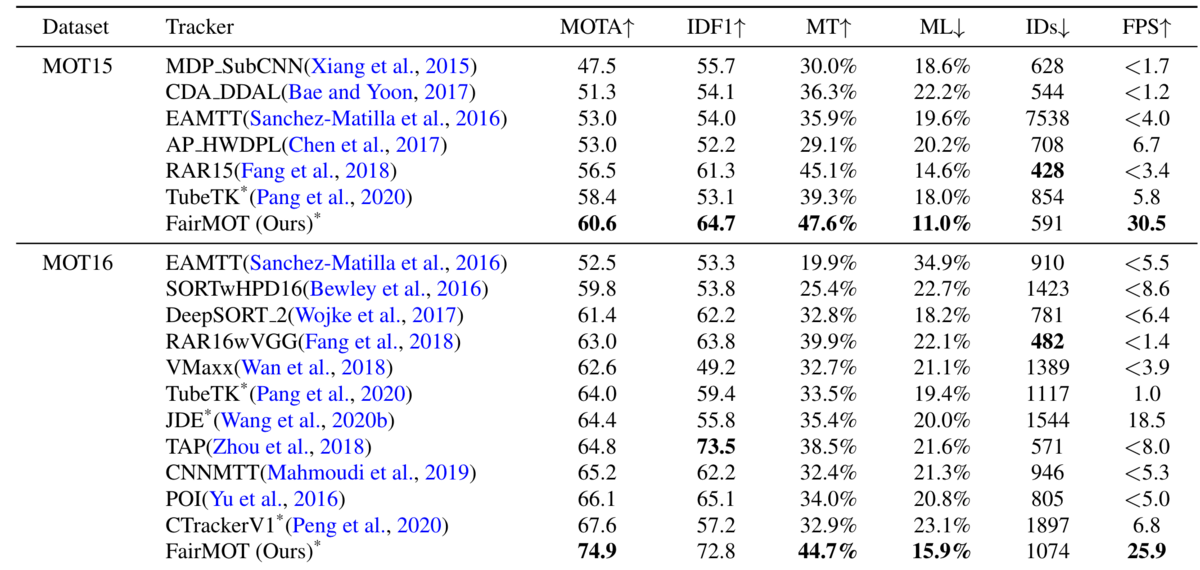
- 表にある通り、多くの指標で既存の手法の精度を超えているだけでなく、推論速度(FPS)においても圧倒的な数字を出しています。
- また、詳細は省きますが多くのablation studyを行っており、著者の指摘した弱点とその解決策を丁寧に調査しています。
感想
- 既存研究の問題点を分析し、徹底したablation studyを行うなど分析方法そのものもとても参考になる論文でした。構成自体はシンプルですが、そこに行き着くまでには相応の努力が必要なんだなと考えさせられます。
YOLOはもう古い?アンカーボックスフリーの物体検出モデルCenterNet
ディープラーニングによる物体検出モデルと聞くとYOLOを真っ先に思い浮かべる人が多いのではないでしょうか。
YOLOはアンカーボックスと呼ばれる、bounding boxの候補を予め定義したものを利用する手法です。
ただ数年前よりこのアンカーボックスを活用しない手法が発表されており、今回はその1つである「CenterNet」を提案した論文「Objects as Points」を紹介します。
検出精度と実行速度を兼ね備えたバランスの良いモデルなので、自動車やスマホなどのエッジデバイスでの物体検出を検討されている方は要チェックです。
arxiv.org
論文の概要
基本的なアイデア

- 一般にbounding boxは物体の左上と右下の2点で表されますが、CenterNetでは物体中心の1点で表現します。幅や高さといった他の情報は中心の画像特徴量から予測されます。
- 物体検出の場合はkeypointのheatmap, local offset, object sizeを出力します。
- heatmapは中心点を特定するためのもので、W/R × H/R × Cの次元を持ちます。Cは物体検出の場合は分類するクラスの数に相当します。Rは画像のダウンサンプル比です。論文ではR=4となっており、入力画像を高さ、幅ともに1/4にした大きさのheatmapが出力されるということです。
- heatmapのground truthは当然物体中心にありますが、ガウシアンカーネルによって周囲にも広げているようです。
- ダウンサンプルによる離散化誤差を補償するためにlocal offsetも予測されます。こちらはW/R × H/R × 2(x, y方向)の次元です。物体サイズ(幅と高さ)も同様にW/R × H/R × 2の次元を持ちます。
- 学習時はheatmap, local offset, object sizeのそれぞれの誤差に係数を掛けて足し合わせたものが使われます。
- 推論時はまずkeypoint heatmapで周囲の8pixelよりも値の大きい極大点を抽出していきます。heatmapの値を推論のconfidence(信頼値)とみなして上位100点を選びます。
- 選ばれた点に対応するlocal offsetとobject sizeによってbounding boxの左上、右下の点を生成します。
- anchor boxを使うモデルではここでNMS(non-maxima suppression)によって被っていて不要なbounding boxを削りますが、CenterNetではNMSは不要です。
- 論文曰く、heatmapで極大点を探す処理がNMSの代わりになっており、これは3×3のmax poolingで実装できるので効率的でもあるとのこと。
モデル構造

- モデル自体はシンプルでbackboneと呼ばれるCNNによる特徴抽出器と、headと呼ばれる各出力を生成する全結合のNNの組み合わせです。
他モデルとの性能比較
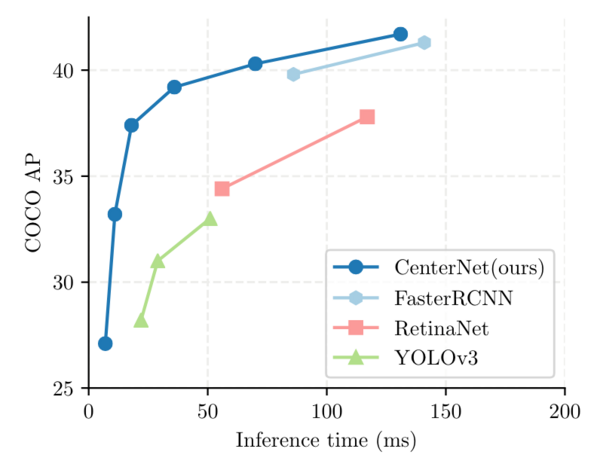
- 縦軸がAverage Precision, 横軸が推論時間ということでグラフの左上にあるほど速くて正確なモデルになります。精度だけを比べると当時でもより良いモデルはありましたが、実行速度と精度を両立しているのはこのCenterNetでした。
- なおheatmapの性質上、同じクラスの異なる物体が同じ中心点を共有すると検出不可になります。
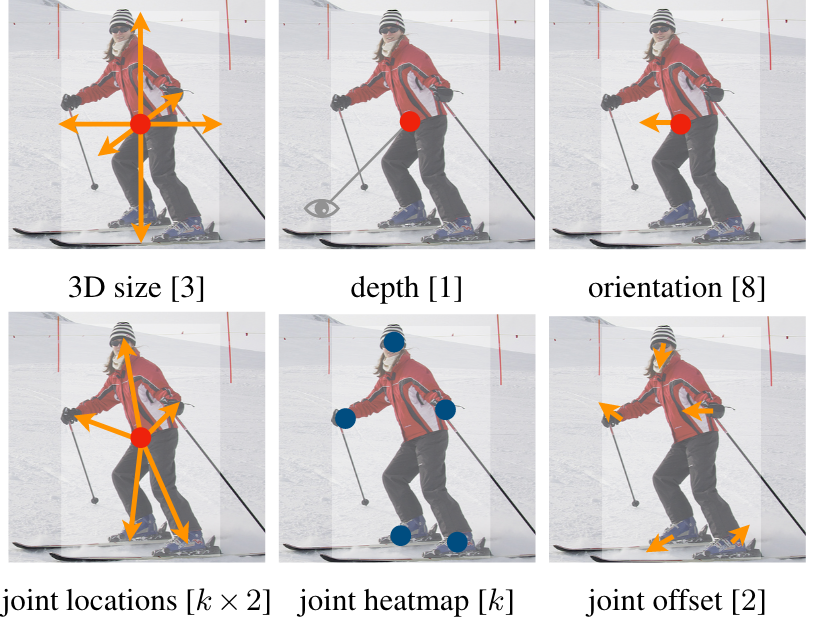
- 本記事では触れませんでしたが、headを交換することで3Dの物体検出や人のpose推論も可能です。
感想
- 近年はDINOv2のような大量のデータと巨大なTransformerによる基盤モデルが主流になっているように感じますが、エッジデバイスでの実行を考えるとCenterNetのような軽量モデルの需要もまた増えてきそうです。
- 余談ですが同時期に別の「CenterNet」という名前の物体検出モデルが発表されており、私は間違えてそっちの論文を読んでいました…シンプルな名前のモデル名は被ることが多いので、読む前に気をつけねばと反省しました。
関連記事
- DINOv2に関する過去記事aburaku.hatenablog.com
- (外部リンク)Courseraの創始者でもあるAndrew Ng先生もエッジAIが今後増えるという予測をしていました。www.deeplearning.ai