物体検出と一体化したreal-timeなトラッキングモデルFairMOT
動画内で検出した物体が以降のフレームのどの物体に対応するかを解く問題はMulti-object tracking(MOT)と呼ばれ、近年ではこれにディープラーニングで取り組む研究も増えています。
今回はその中でもreal-time性の高いFairMOTを提案した論文「FairMOT: On the Fairness of Detection and Re-Identification in Multiple Object Tracking」を紹介します。
arxiv.org
論文の概要
既存研究の課題
- 既存研究の多くはdetectionモデル+associationモデルの2つの異なるモデルによるアプローチです。
- ここでassociationモデルは異なるフレーム間で検出されたbounding boxを対応付けするためのre-ID特徴量を抽出するものです。
- このアプローチは2つのモデル間で特徴をシェアできないため、推論速度が遅くリアルタイムの推論に向かないという欠点があります。

- 当然1つのモデルで物体検出とre-ID出力を行うモデルの研究もありますが、trackingの精度が明らかに落ちている問題があります。著者はその原因として以下の3点を挙げています。
- 多くのdetectionモデルで採用されるanchor boxはre-IDに適していない。anchorで物体検出→re-IDという順番では2つのタスクが競合した時に物体検出を優先してしまう。また混雑したシーンではanchorと物体が1対1対応しないことも問題になる。
- detectionとtrackingに必要な特徴量は異なる。trackingは同じclassの別個体を見分ける必要があるのでより細かな情報が必要だが、detectionでは同じclassなら別の個体でも近い特徴であるべき。
- 2つのタスクで特徴量の次元が異なる。re-IDは512や1024が使われ、一般的にdetectionよりも大きい。大きすぎるre-IDの次元は全体のバランスを損なう。
- FairMOTは上記の問題によって引き起こされるdetectionとre-IDタスク間の不公平を丁寧に取り除いた設計になっています。
FairMOTの構成
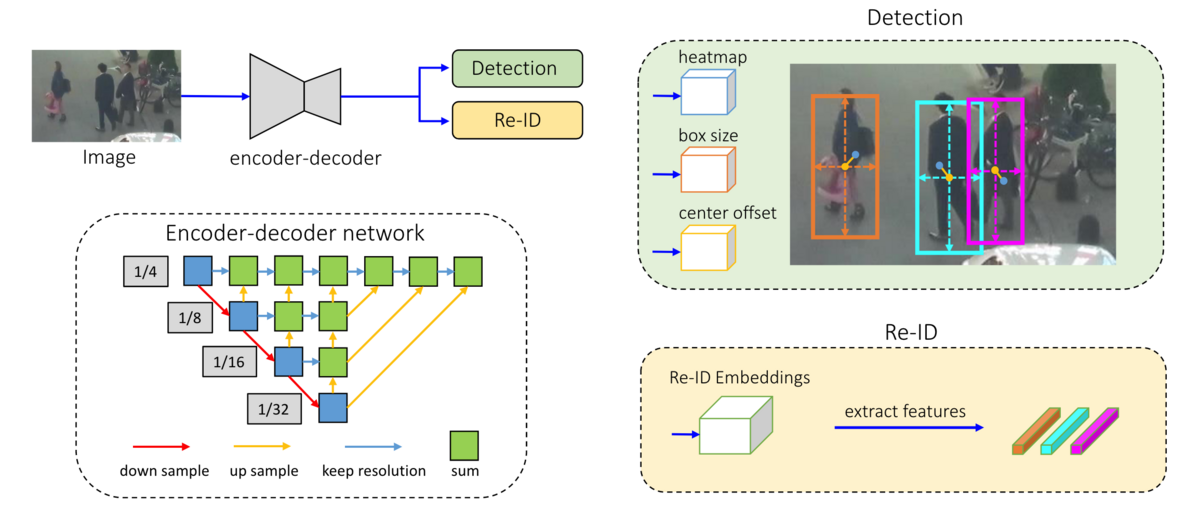
FairMOTの構成は上図のように画像から特徴量を抽出するBackBoneにDetectionとRe-IDブランチを並列に繋げたものです。
BackBone
- BackBoneにはDeep Layer Aggregation(DLA)と呼ばれる、異なるresolutionの特徴量を混ぜ合わせる構造が採用されています。backboneの出力は元のサイズから縦横それぞれ1/4になります。
Detectionブランチ
- 前述の通りanchorベースの物体検出モデルは向かないということで、anchorフリーモデルのCenterNetを採用しています。
- これは物体の中心点のheatmap、離散化誤差を補償するoffset、そして物体のサイズをそれぞれ出力するheadからなります。詳しくは以前記事にしていますので、そちらを参照ください。aburaku.hatenablog.com
Re-IDブランチ
- Re-IDの特徴量はheatmapの各点毎に128次元を持ちます。
- 学習データ内の全objectを分類する問題として学習を行います。loss計算時は物体中心点の特徴量だけが考慮されます。
- Re-ID lossとdetection lossは学習可能なパラメータによってバランスがとられます。(Uncertainty loss)
推論時の流れ
- まずはCenterNetと同様の流れでDetection結果を元にbounding boxを生成していきます。
- 具体的には3*3のmax poolingでheatmapの極大点を抽出(従来のNMSに相当)し、その中で閾値以上のconfidenceのものだけを残します。
- その後box sizeとoffsetからbboxを求め、また物体中心点のRe-id特徴量を抽出します。
- その後2段階のマッチング戦略で以前のフレームのbounding boxと検出されたbounding boxを紐づけます。
- 1st: Kalman filterで次のフレームでの位置を予測し、検出されたbox達とのMahalanobis距離を計算する。また、Re-id特徴量同士のcosine距離も求めてそれらの距離を係数を掛けて足し合わせた値でマッチング。
- 2nd: 残ったboxをIoUを元にマッチングする。そこでも残った新規検出boxを新しいtrackとみなし、マッチしなかった過去のtrackは30frame保存する。
性能比較
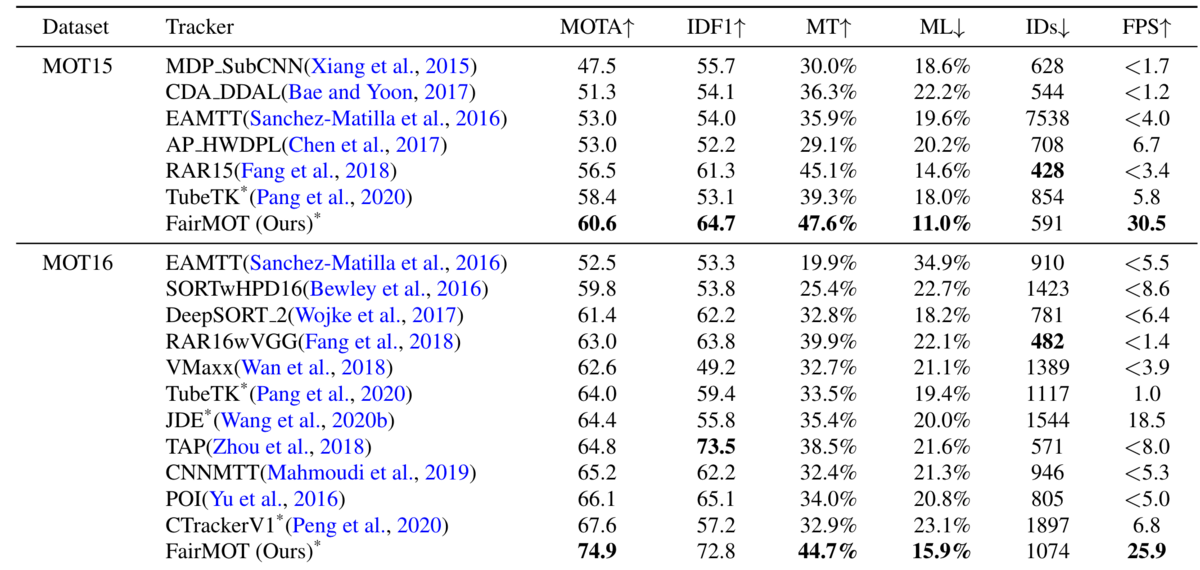
- 表にある通り、多くの指標で既存の手法の精度を超えているだけでなく、推論速度(FPS)においても圧倒的な数字を出しています。
- また、詳細は省きますが多くのablation studyを行っており、著者の指摘した弱点とその解決策を丁寧に調査しています。
感想
- 既存研究の問題点を分析し、徹底したablation studyを行うなど分析方法そのものもとても参考になる論文でした。構成自体はシンプルですが、そこに行き着くまでには相応の努力が必要なんだなと考えさせられます。