論文読み MaskViT: Masked Visual Pre-Training for Video Prediction
この記事の概要
- 動画を入力して将来のフレームを予測するVideo Predictionの論文「MaskViT: Masked Visual Pre-Training for Video Prediction」を紹介します。arxiv.org
- モデルによる予測の例は以下のリンクから見ることができます。maskedvit.github.io
- なおこの論文のことはDeepLearning.AIのニュースレター、THE BATCHで知りました。英語ですがこちらでも解説が読めます。www.deeplearning.ai
論文の概要
- training
- 学習は2段階で行われ、まずはVQGANで画像を16×16のtokenに圧縮します。これはpixelをtokenにするとあまりに計算量が増えてしまうからです。
- Masked Visual Modeling(MVM)と呼ばれるタスクで学習しています。これは最初のフレームだけをそのままに、以降のフレームの特徴量を50~100%の割合でランダムにマスクして、続くTransformerでマスクなしの特徴量を予測するというものです。
- Transformerは全時間でself-attentionを行うと計算量が膨大になるため、2つに分けて計算されています。1つはフレーム毎に計算して空間情報を取得するもの、もう1つはフレームにまたがって計算する時間-空間情報を取得するものです。

- inference
- 学習ではマスクされた特徴量を復元するモデルが得られているので、推論時も同様の入力をします。本論文では最初にt=0以外の特徴量を全てmaskしたものを入力し、その予測結果にマスクを付与したものを再度入力して徐々にマスクを減らしていくという処理を繰り返します。
- 最後にVQGANのデコーダで特徴量から画像を復元します。

- 予測結果の例
- 画像が揺らいでいる部分があるなど、不自然さはありますが入力1枚でここまで予測できるのは凄いと思います。

感想
- 話題のChatGPTでは文章中の単語列から次の単語を予測するというシンプルなタスクでpre-trainingすることで様々なタスクで高い性能を実現しています。Computer Visionにも同じような流れが来るとは思いますが、どのようなタスクでpre-trainingすると良いのか興味深いです。
- 本論文でも冒頭で触れられていますが、脳の知覚は予測機構によって成り立つという予測符号化モデル(predictive coding)理論があります。脳の仕組みを模倣するというのはディープラーニング研究の1つの指針であるため、video predictionに限らず参考にしている論文がそれなりにあるようです。自分も一時脳科学の本を読み漁りましたが、日本語の本では以下がわかりやすかったと思います。
")
論文読み MetaFormer Is Actually What You Need for Vision
記事の概要
- 前回の記事でVision Transformerのself-attentionをMLPに置き換えても性能は変わらないという論文を紹介しました。aburaku.hatenablog.com
- 今回紹介する論文はさらに一歩進み、特徴量をmixするパートは何でもよくて、それ以外の構造自体が重要ではないかという提案をしています。arxiv.org
論文の概要
- Transformerにおけるself-attention、MLP-mixerにおけるtoken-mixing MLPを"Token Mixer"として抽象化したMetaFormerを提案しています。
We thus hypothesize compared with specific token mixers, MetaFormer is more essential for the model to achieve competitive performance.
- PoolingするだけのシンプルなToken Mixerが他と同程度の性能を出していることが、Token Mixerの中身よりもそれ以外の構造の方が重要という主張を支持しています。

- 画像分類(ImageNet-1K), 物体検出(COCO benchmark), セマンティックセグメンテーション(ADE20K)でCNNなどの既存モデルよりも少ないパラメータ、計算量で同等の精度が示されています。
- 興味深いのがablation study。これによるとnormalizationとResidual connection、Channel MLPが必須であることがわかります。また、mixerにpoolとattentionを組み合わせると精度が上がっています。

感想
- 著者の言うようにこの考えが自然言語処理でも共通なのかは気になります。画像処理と言語処理が同じシンプルなネットワークで実現できるなら面白いですね。
Moreover, it is interesting to see whether PoolFormer still works on NLP tasks to further support the claim “MetaFormer is actually what you need” in the NLP domain.
- まずVision Transformerを理解したいという方には以下の本がおすすめです。日本語で読める質の高い教科書があるのはありがたいですね。

論文読み MLP-Mixer: An all-MLP Architecture for Vision
記事の概要
- Computer Visionの分野ではCNNとVision Transformer以外にMLPをベースにしたモデルが台頭しているということを聞き、一体どういうことなのか調べました。
- あまりいい感じの解説記事が見つからなかったので、元論文MLP-Mixer: An all-MLP Architecture for Visionをまとめました。
論文の概要
- アーキテクチャは基本的にViTにそっくりです。大きく異なる点はMultiHeadAttentionがMixer Layerに代わり、positional encodingが無いことでしょうか。
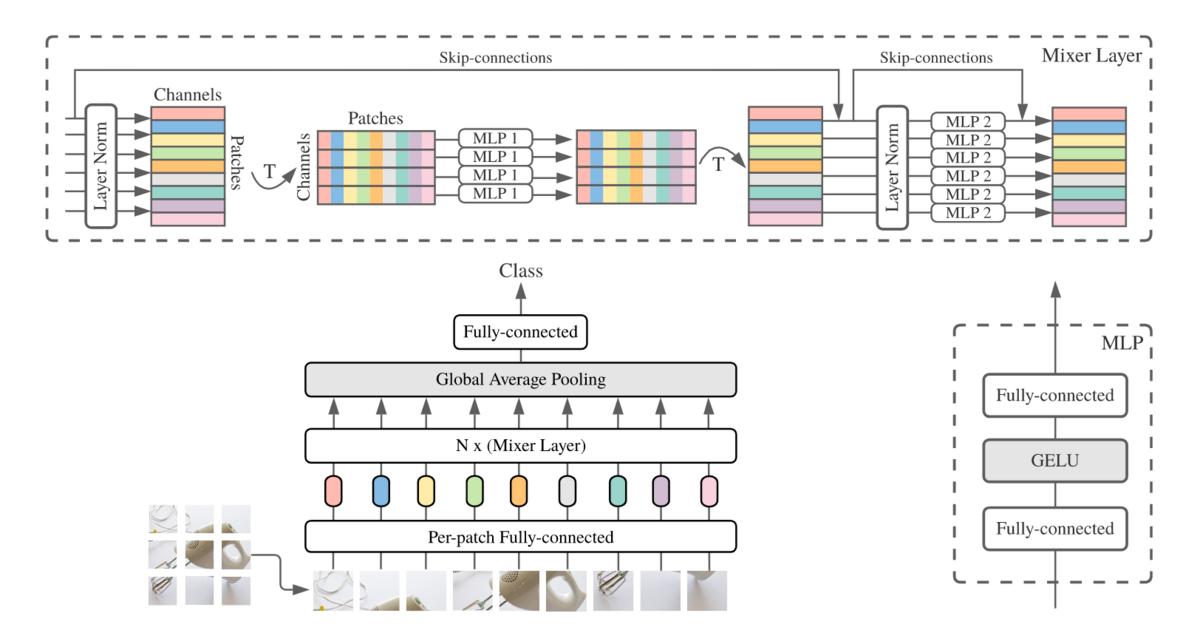
- Mixer Layerはチャンネル毎に独立してパッチ間で情報を混ぜるtoken-mixing MLPと、パッチ毎にチャンネル間で情報を混ぜるchannel-mixing MLPの組み合わせです。
- positional encodingがなくても良いのか…と思いましたが、パッチの順番とパッチ内のピクセルを並び替えてもモデル性能が変わらないという実験結果も添えられていました。

- ViTと同様に事前学習に使うデータ量が少ない場合はCNNに比べると性能は落ちますが、データが増えるにつれて性能が逆転していきます。
- その傾向がMixerの方がViTより強いです。その理由として著者は以下のように述べています。要はMixerの方が前提としていることが少ないので、より生のデータから学ぶ必要があるということですかね。
One could speculate and explain it again with the difference in inductive biases: self-attention layers in ViT lead to certain properties of the learned functions that are less compatible with the true underlying distribution than those discovered with Mixer architecture.

onnxファイルからパラメータ(weight, bias)を抽出する
やりたいこと
- ニューラルネットワークの表現形式の一つであるonnxファイルからパラメータを取り出したい。
- PyTorchなどのフレームワークで一旦読み込んでからパラメータを取り出すこともできるかと思いますが、onnxだけで完結する方法を共有します。
実装
- サンプルとしてonnxのリポジトリにあるyolo v3のonnxを使いました。
- onnxをNetronで可視化した一部が以下の通り。最初のConvレイヤーのweightの名前は「W74」らしいです。

- 以下のsnippetでW74のweightをprintしています。Netronで見た値と同じであることが確認できます。
参考
「ゼロから始める情報発信」を読んで
個人の情報発信について考えました
- これまで何度もブログを作っては飽きを繰り返してきましたが、今回はそこそこ続いているので今後も継続したいところ。
- ということで個人での発信を20年以上続けられている方の電子書籍を読んで、発信の意義と続けるための方法を考えてみました。

参考になった記述
- No Output, No Value。どんなにすごいことをしても、誰にも知られなければ存在しないのと同じ。
- 以前読んだ「遅咲きエンジニア」の記事を思い出しました。この方は28歳にエンジニアになり、個人のアウトプットを継続することで今の地位を得られたとのこと。logmi.jp
- 目的は「楽しみながら継続的に一定のペースでネット上にコンテンツを作成して情報発信をすること」
- 情報発信の本はいくつか存在しますが、SEOでアクセスを増やして収入を得ることに特化したものが多い印象です。本書はエンジニアである著者自身の経験に基づいているので自分には合っていました。
- 「自分が困ったこと」を書く。とくにGoogleで調べても正しい情報が出てこないもの。ブログのネタになるかもという発想を持てば、困った時も前向きになれる。
- Googleで調べていくつかの記事やQAを見てようやく解決策を見つけた時なんかも記事にした方が誰かの助けになりそうです。
- 情報発信のハードルを低くする。上達してから初めて人に見せるという考えでは上手くいかない。
- 自分はまさにこれ。今の時代ネットでいくらでも自分より凄い人がわかりやすい解説記事を出しているので、自分が今更記事を書く意味はあるのか?と意欲を失ってしまいがちです。
- 成長物語や初心者向けにまとめた情報は人気の出るコンテンツの1つ。自分が必要としている情報であれば、少なくとも無駄にはならない。
- これは真似してみたい。自分は社会人からプログラミングを始めたので、そういう人間だからこそ書ける記事でもあると思いますので。
- ブログを特化型か雑記型で迷った場合は取りあえず雑記型がいい。発信を続けていけば知らず知らずに自分の特色は出てくる。
- 基本的には機械学習メインで行きますが、ネタがあればたまに技術以外のことも書いていこうと思います。
なぜ発信した方がいいのか?
- 最近自分が発信したいと思うようになったきっかけは、自分のモチベーションを保つためです。初心者の頃はやればやる程伸びていきましたが、ある時点から伸び悩み、ハイレベルなエンジニアとの差を実感して意欲が失われていきました。
- 何か自分の意欲を掻き立てるテーマがあるはずだ、と色々と手を出してみましたが、そんな都合の良いものは存在するわけがなく、すぐに飽きてしまいほとんど何も得ないということを繰り返していました。
- 自分のような人間は、比較的興味を持てそうなテーマを深堀りして、自分のエンジニアとしての価値を高めることができれば十分だと思います。下手に一生かけて追求できそうな問題を探そうとするといつまで経っても腰を据えて取り組むことができません。
- なので1~数ヶ月くらい1つのテーマを継続できれば十分とハードルを下げつつ、発信する頻度を増やしてフィードバックを得て継続するためのモチベーションを維持できればと考えています。
Andrej KarpathyのGPT解説動画
本記事の概要
TeslaでAI開発のディレクターを務め、現在はChatGPTで有名なOpenAIで働くAndrej KarpathyのGPT解説動画[Let's build GPT: from scratch, in code, spelled out.]を紹介します。
www.youtube.com
動画の概要
- ChatGPTにも使用されている言語モデルGPT3と同等のモデルを実装していきます。
- データセットは1MB程度の小さなものなのでそこまでの精度は出ません。あくまでモデルのアーキテクチャを学ぶのが目的のようです。
- 実装は全てPyTorchで、もちろん動画で実装されるコードは全て公開されています。GitHub - karpathy/ng-video-lecture
- 2時間の動画ですが、データの前処理から始まり、シンプルなモデルから徐々にGPTに近づけていくスタイルでとても理解しやすい解説でした。
個人的な学び
- GPTの構造はTransformerの元論文、Attention Is All You NeedのDecoder側(右半分)を微修正したものとのこと。

import torch
import torch.nn.functional as F
B, T, C = 2, 8, 2
x = torch.randn(B, T, C)
tril = torch.tril(torch.ones(T, T))
wei = torch.zeros((T, T))
wei = wei.masked_fill(tril==0, float("-inf"))
wei = F.softmax(wei, dim=1)
wei @ x
tril = torch.tril(torch.ones(T, T))
wei = wei / wei.sum(1, keepdim=True)
wei @ x
google colabのTPUをPyTorchで使う
問題
- google colabのTPUをPytorchで使いたい。
- ググって出てくるセットアップをするとエラーが出る。
# !pip install cloud-tpu-client==0.10 https://storage.googleapis.com/tpu-pytorch/wheels/torch_xla-1.9-cp37-cp37m-linux_x86_64.whl ERROR: torch_xla-1.9-cp37-cp37m-linux_x86_64.whl is not a supported wheel on this platform.
学び
- 大体のことは適当にググって上の方に出てくる方法で解決するけど、インストール関連など公式ページを見たほうが良いトピックもあるので気をつけよう。