YOLOはもう古い?アンカーボックスフリーの物体検出モデルCenterNet
ディープラーニングによる物体検出モデルと聞くとYOLOを真っ先に思い浮かべる人が多いのではないでしょうか。
YOLOはアンカーボックスと呼ばれる、bounding boxの候補を予め定義したものを利用する手法です。
ただ数年前よりこのアンカーボックスを活用しない手法が発表されており、今回はその1つである「CenterNet」を提案した論文「Objects as Points」を紹介します。
検出精度と実行速度を兼ね備えたバランスの良いモデルなので、自動車やスマホなどのエッジデバイスでの物体検出を検討されている方は要チェックです。
arxiv.org
論文の概要
基本的なアイデア

- 一般にbounding boxは物体の左上と右下の2点で表されますが、CenterNetでは物体中心の1点で表現します。幅や高さといった他の情報は中心の画像特徴量から予測されます。
- 物体検出の場合はkeypointのheatmap, local offset, object sizeを出力します。
- heatmapは中心点を特定するためのもので、W/R × H/R × Cの次元を持ちます。Cは物体検出の場合は分類するクラスの数に相当します。Rは画像のダウンサンプル比です。論文ではR=4となっており、入力画像を高さ、幅ともに1/4にした大きさのheatmapが出力されるということです。
- heatmapのground truthは当然物体中心にありますが、ガウシアンカーネルによって周囲にも広げているようです。
- ダウンサンプルによる離散化誤差を補償するためにlocal offsetも予測されます。こちらはW/R × H/R × 2(x, y方向)の次元です。物体サイズ(幅と高さ)も同様にW/R × H/R × 2の次元を持ちます。
- 学習時はheatmap, local offset, object sizeのそれぞれの誤差に係数を掛けて足し合わせたものが使われます。
- 推論時はまずkeypoint heatmapで周囲の8pixelよりも値の大きい極大点を抽出していきます。heatmapの値を推論のconfidence(信頼値)とみなして上位100点を選びます。
- 選ばれた点に対応するlocal offsetとobject sizeによってbounding boxの左上、右下の点を生成します。
- anchor boxを使うモデルではここでNMS(non-maxima suppression)によって被っていて不要なbounding boxを削りますが、CenterNetではNMSは不要です。
- 論文曰く、heatmapで極大点を探す処理がNMSの代わりになっており、これは3×3のmax poolingで実装できるので効率的でもあるとのこと。
モデル構造

- モデル自体はシンプルでbackboneと呼ばれるCNNによる特徴抽出器と、headと呼ばれる各出力を生成する全結合のNNの組み合わせです。
他モデルとの性能比較
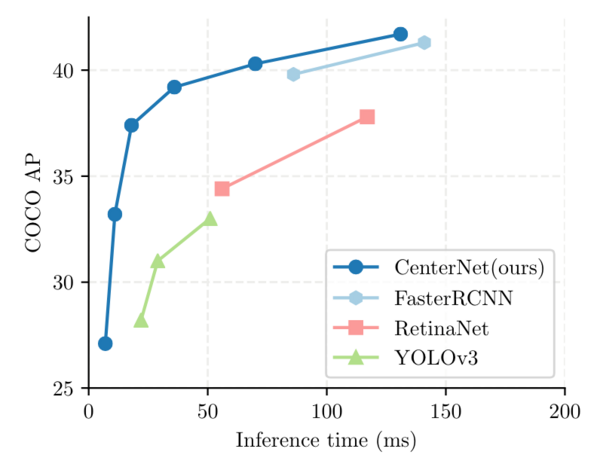
- 縦軸がAverage Precision, 横軸が推論時間ということでグラフの左上にあるほど速くて正確なモデルになります。精度だけを比べると当時でもより良いモデルはありましたが、実行速度と精度を両立しているのはこのCenterNetでした。
- なおheatmapの性質上、同じクラスの異なる物体が同じ中心点を共有すると検出不可になります。
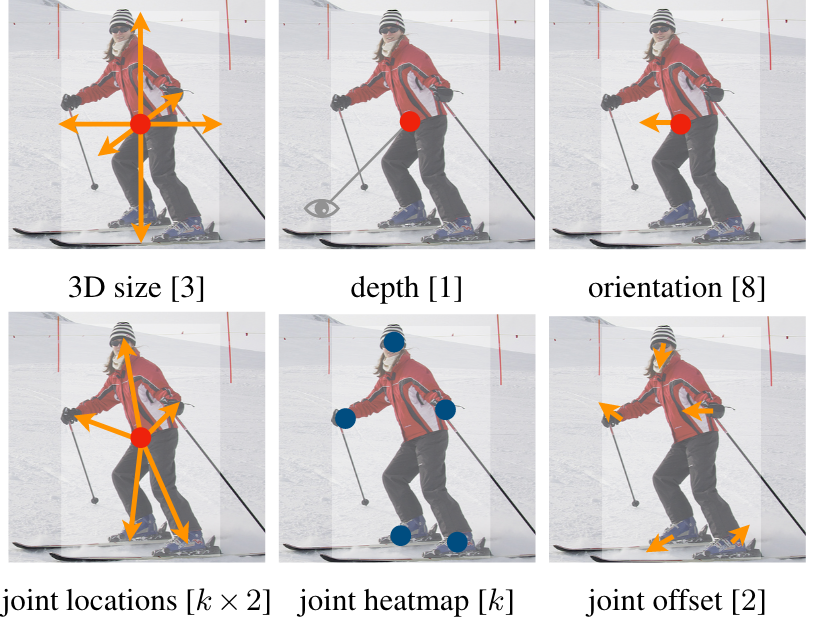
- 本記事では触れませんでしたが、headを交換することで3Dの物体検出や人のpose推論も可能です。
感想
- 近年はDINOv2のような大量のデータと巨大なTransformerによる基盤モデルが主流になっているように感じますが、エッジデバイスでの実行を考えるとCenterNetのような軽量モデルの需要もまた増えてきそうです。
- 余談ですが同時期に別の「CenterNet」という名前の物体検出モデルが発表されており、私は間違えてそっちの論文を読んでいました…シンプルな名前のモデル名は被ることが多いので、読む前に気をつけねばと反省しました。
関連記事
- DINOv2に関する過去記事aburaku.hatenablog.com
- (外部リンク)Courseraの創始者でもあるAndrew Ng先生もエッジAIが今後増えるという予測をしていました。www.deeplearning.ai