Andrej KarpathyのGPT解説動画
本記事の概要
TeslaでAI開発のディレクターを務め、現在はChatGPTで有名なOpenAIで働くAndrej KarpathyのGPT解説動画[Let's build GPT: from scratch, in code, spelled out.]を紹介します。
www.youtube.com
動画の概要
- ChatGPTにも使用されている言語モデルGPT3と同等のモデルを実装していきます。
- データセットは1MB程度の小さなものなのでそこまでの精度は出ません。あくまでモデルのアーキテクチャを学ぶのが目的のようです。
- 実装は全てPyTorchで、もちろん動画で実装されるコードは全て公開されています。GitHub - karpathy/ng-video-lecture
- 2時間の動画ですが、データの前処理から始まり、シンプルなモデルから徐々にGPTに近づけていくスタイルでとても理解しやすい解説でした。
個人的な学び
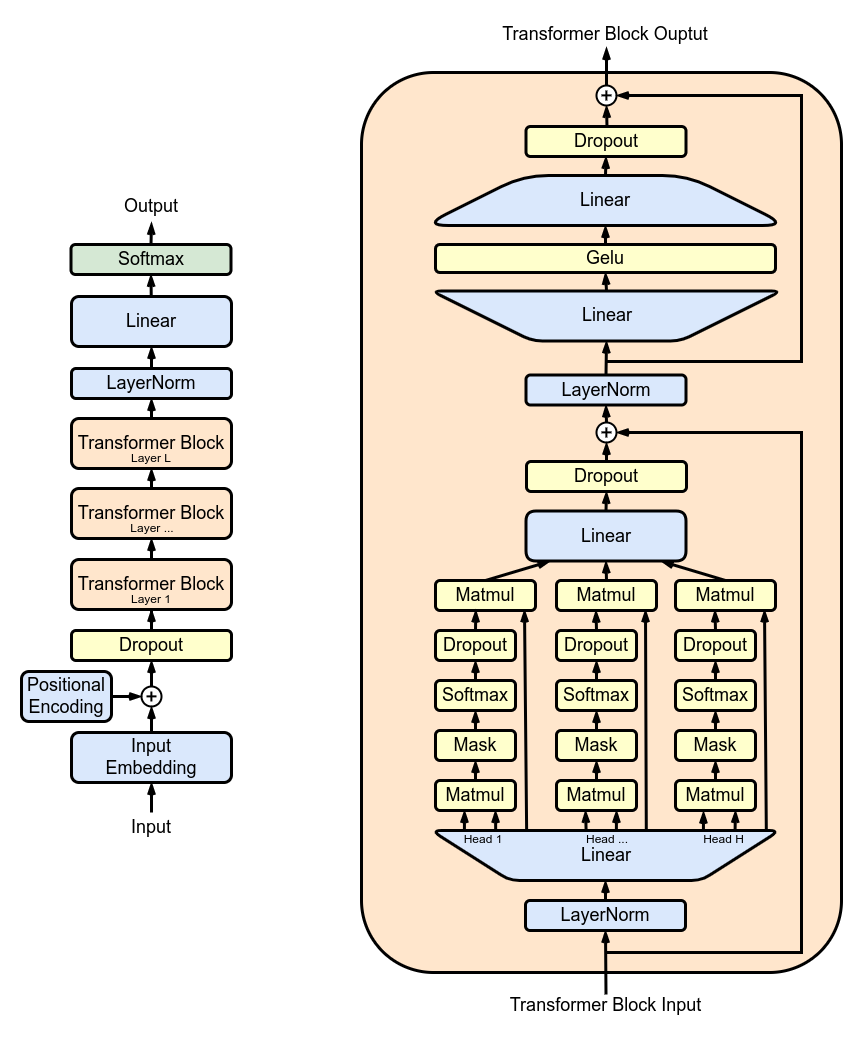
- GPTの構造はTransformerの元論文、Attention Is All You NeedのDecoder側(右半分)を微修正したものとのこと。

import torch
import torch.nn.functional as F
B, T, C = 2, 8, 2
x = torch.randn(B, T, C)
tril = torch.tril(torch.ones(T, T))
wei = torch.zeros((T, T))
wei = wei.masked_fill(tril==0, float("-inf"))
wei = F.softmax(wei, dim=1)
wei @ x
tril = torch.tril(torch.ones(T, T))
wei = wei / wei.sum(1, keepdim=True)
wei @ x
