論文読み MLP-Mixer: An all-MLP Architecture for Vision
記事の概要
- Computer Visionの分野ではCNNとVision Transformer以外にMLPをベースにしたモデルが台頭しているということを聞き、一体どういうことなのか調べました。
- あまりいい感じの解説記事が見つからなかったので、元論文MLP-Mixer: An all-MLP Architecture for Visionをまとめました。
論文の概要
- アーキテクチャは基本的にViTにそっくりです。大きく異なる点はMultiHeadAttentionがMixer Layerに代わり、positional encodingが無いことでしょうか。
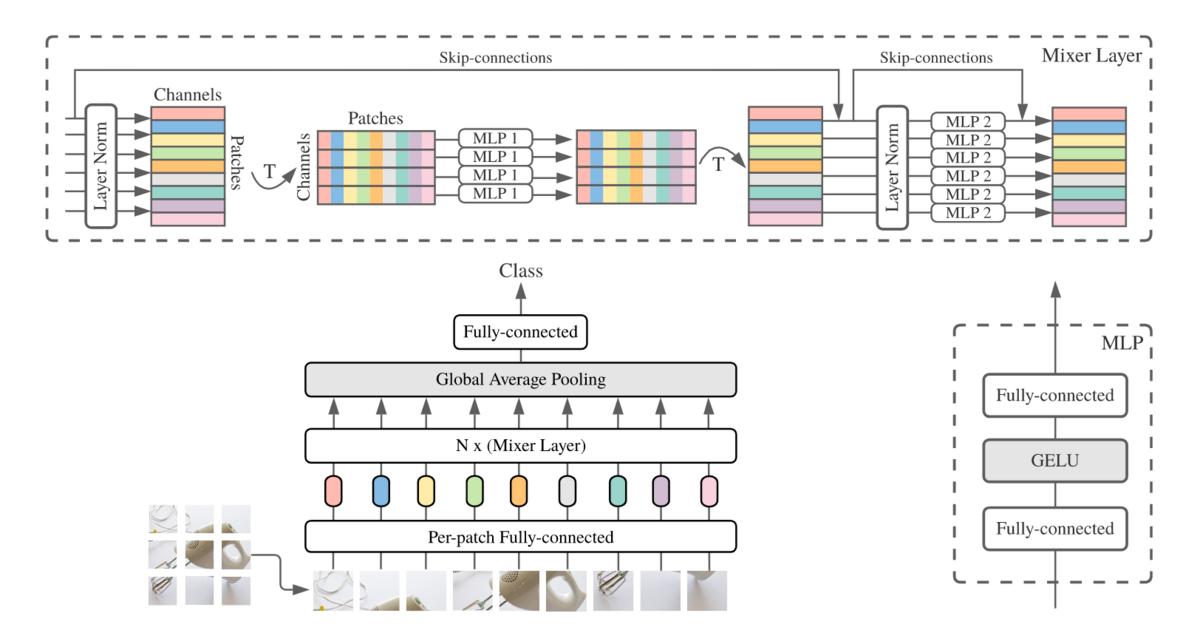
- Mixer Layerはチャンネル毎に独立してパッチ間で情報を混ぜるtoken-mixing MLPと、パッチ毎にチャンネル間で情報を混ぜるchannel-mixing MLPの組み合わせです。
- positional encodingがなくても良いのか…と思いましたが、パッチの順番とパッチ内のピクセルを並び替えてもモデル性能が変わらないという実験結果も添えられていました。

- ViTと同様に事前学習に使うデータ量が少ない場合はCNNに比べると性能は落ちますが、データが増えるにつれて性能が逆転していきます。
- その傾向がMixerの方がViTより強いです。その理由として著者は以下のように述べています。要はMixerの方が前提としていることが少ないので、より生のデータから学ぶ必要があるということですかね。
One could speculate and explain it again with the difference in inductive biases: self-attention layers in ViT lead to certain properties of the learned functions that are less compatible with the true underlying distribution than those discovered with Mixer architecture.
